



Large Language Models (LLMs) have made considerable changes in the way we interact with AI-powered systems, from chatbots to content generation. One crucial aspect of LLM development is their training process, which includes Reinforcement Learning with Human Feedback (RLHF) as a key component. In this informative article, the training process and RLHF are dissected step by step, shedding light on the intricate world of LLMs.
The Canonical LLM Training Pipeline
It's essential to understand the overall LLM training pipeline. Modern transformer-based LLMs, such as ChatGPT and Llama 2, undergo a three-step training procedure:
Pretraining: During this phase, the models acquire knowledge from vast, unlabeled text datasets through a next-word prediction task. This self-supervised learning approach enables the use of extensive datasets without manual labeling.

Pretraining typically occurs on a vast text corpus comprising billions to trillions of tokens. In this context, we employ a straightforward next-word prediction task in which the model predicts the subsequent word (or token) from a provided text.
Supervised Finetuning: In this step, the models refine their performance by learning from instruction-output pairs. A human or another high-quality LLM generates desired responses based on specific instructions, creating a valuable dataset.

The supervised fine-tuning stage involves another round of next-token prediction. This stage involves working with instruction-output pairs, as illustrated in the figure above. In this context, the instruction serves as the input to the model, occasionally accompanied by optional input text, depending on the specific task. The model's output, on the other hand, corresponds to a desired response, mirroring the expected output the model should generate.
Alignment: The alignment phase aims to make LLMs more user-friendly and safer by refining their responses based on human preferences.
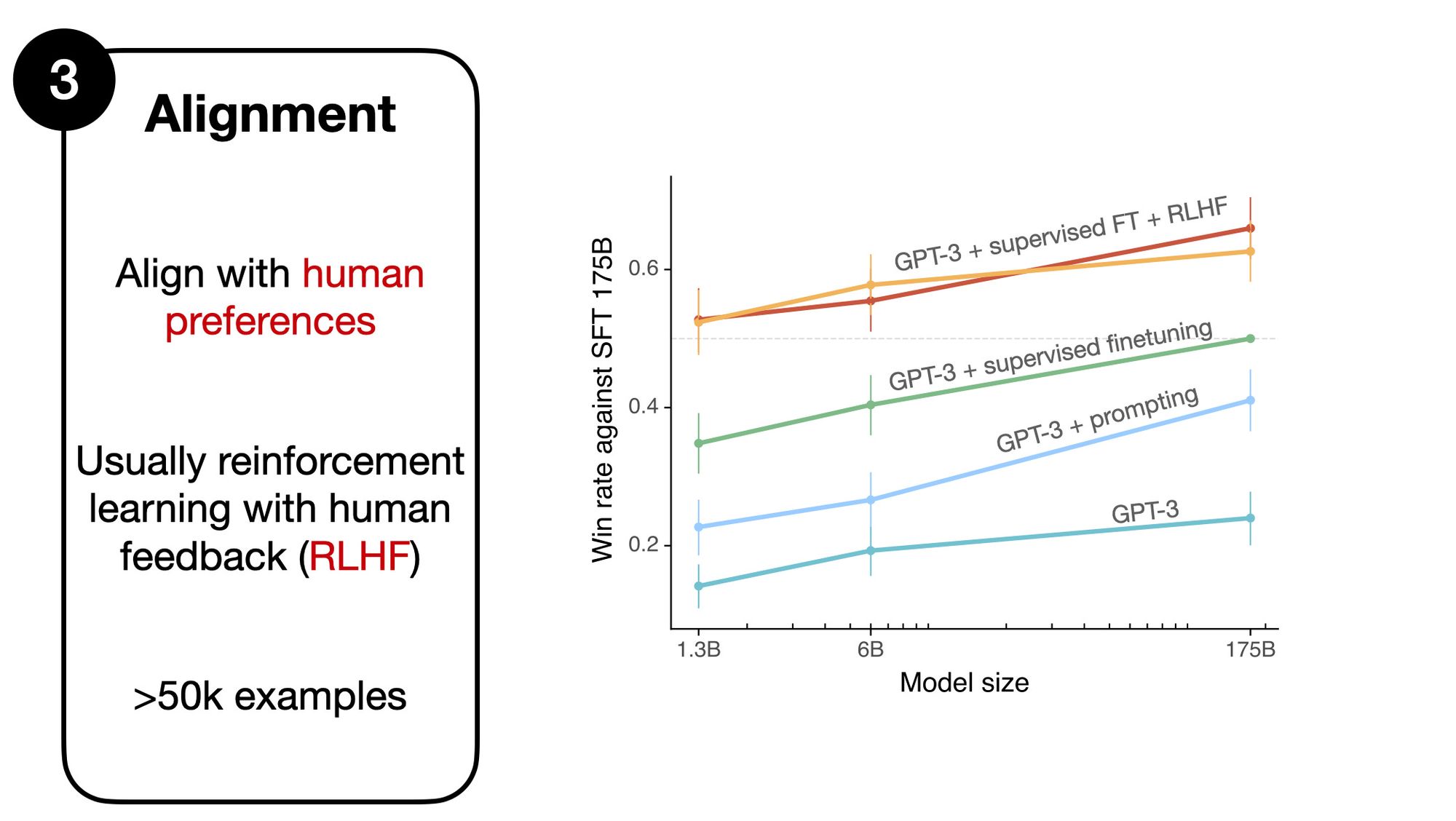
The chart above compares a 175B GPT-3 model after supervised finetuning (faint dotted line) with the other method.
Reinforcement Learning with Human Feedback (RLHF)
RLHF is a pivotal part of the alignment phase, and it involves three distinct steps:
Supervised Finetuning of the Pretrained Model: This initial step creates a base model for further RLHF finetuning. Prompts are sampled, and humans are asked to provide high-quality responses, which are then used to finetune the pre-trained base model.
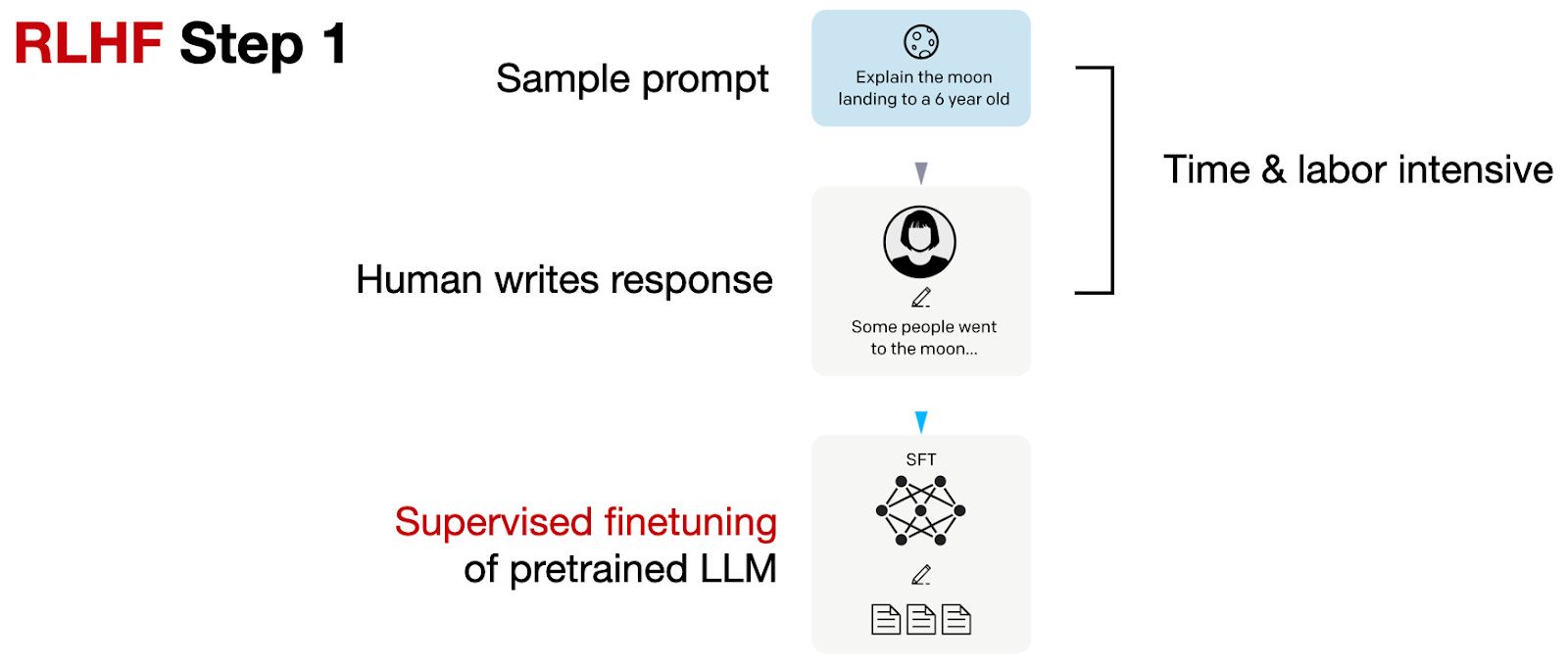
In RLHF step 1, we create or sample prompts (from a database, for example) and ask humans to write good-quality responses. We then use this dataset to finetune the pre-trained base model in a supervised fashion.
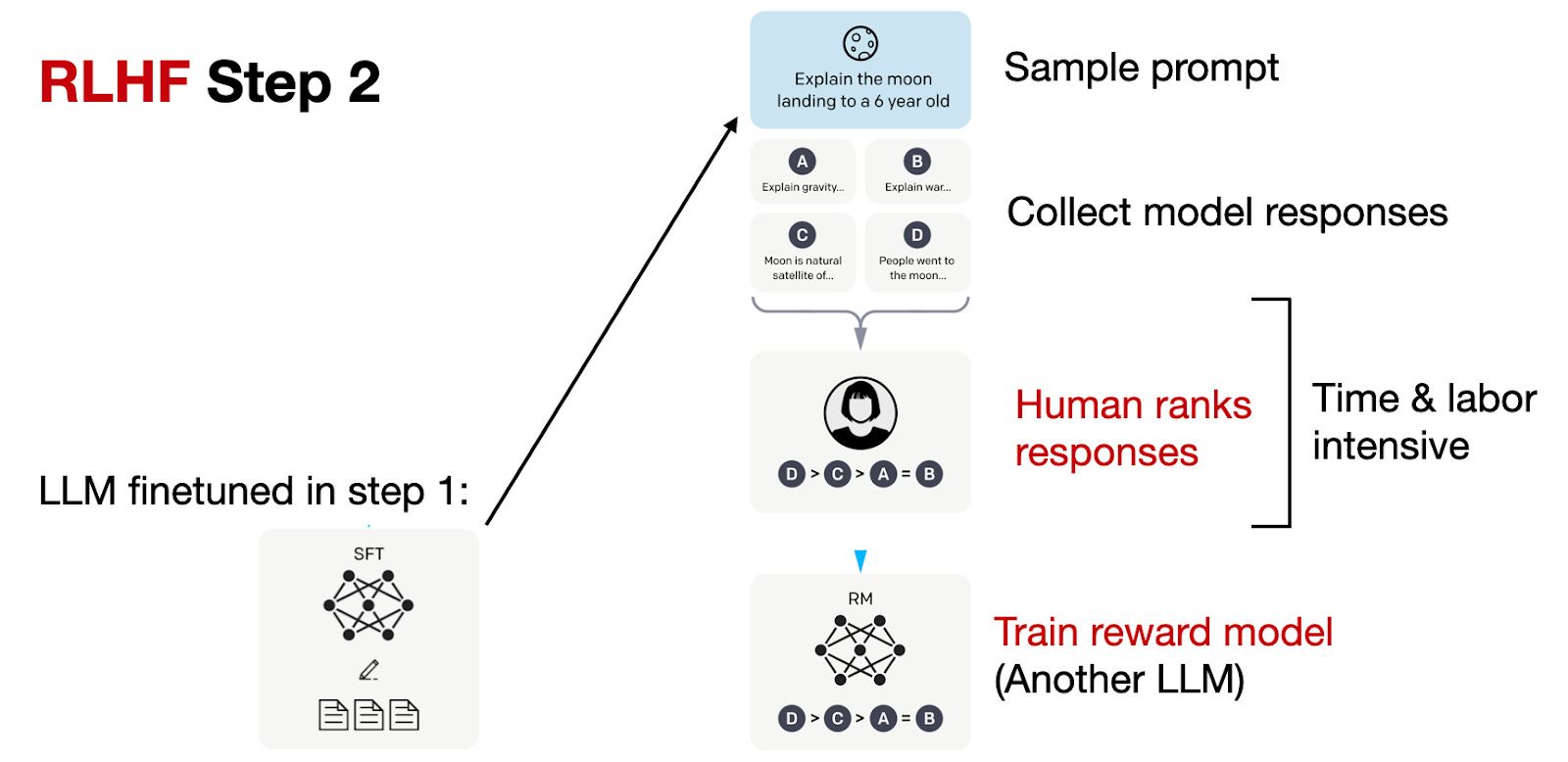
Creating a Reward Model: For each prompt, multiple responses are generated and ranked by humans. These rankings are used to create a reward model, which outputs reward scores for the optimization in the next step.
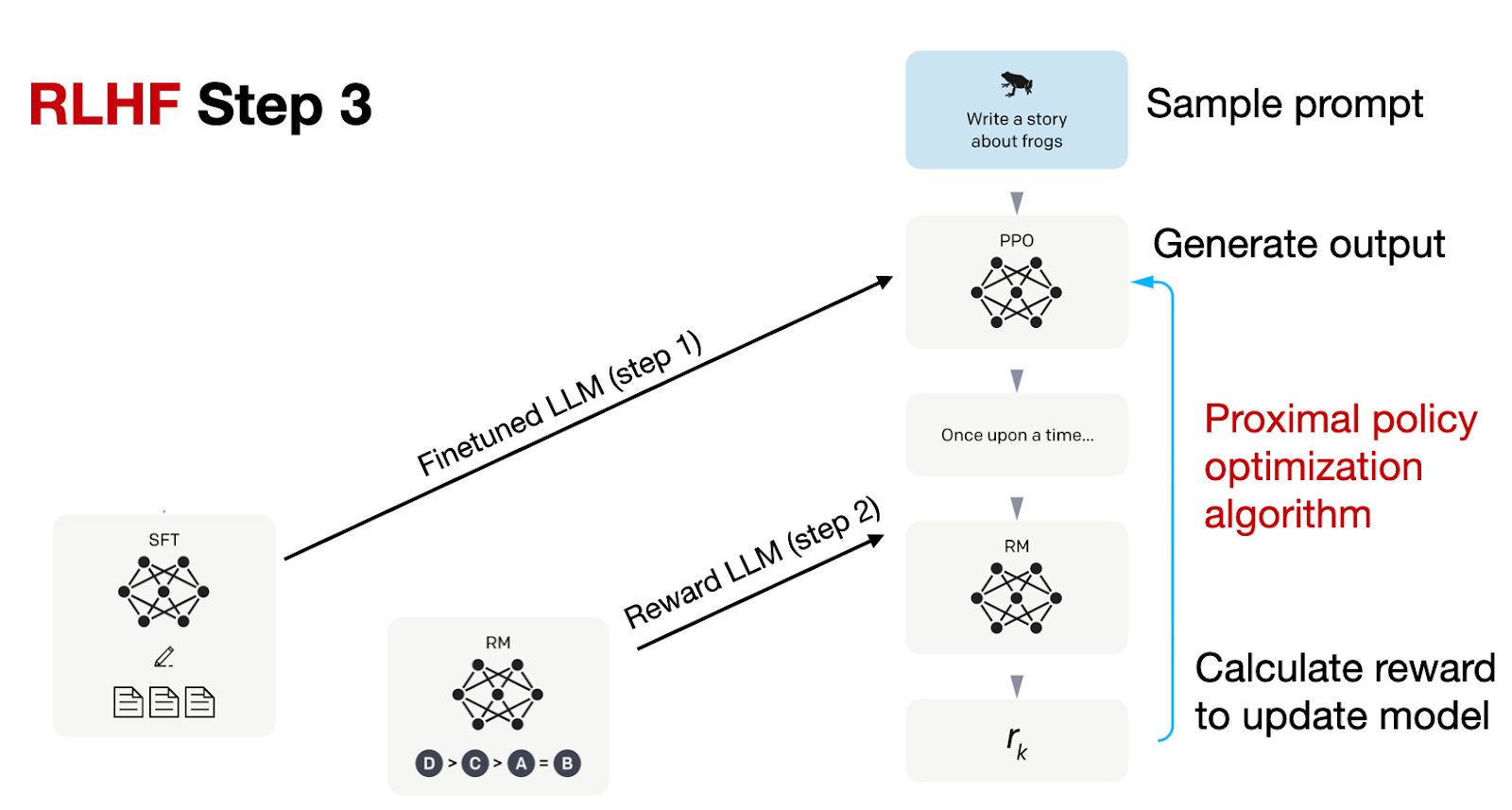
Finetuning via Proximal Policy Optimization (PPO): The final stage involves updating the model using PPO based on the reward scores from the reward model created in the previous step.
Comparing ChatGPT and Llama 2
Both ChatGPT and Llama 2 utilize RLHF in their training pipelines. However, there are significant differences between the two approaches:
- Llama 2 creates two reward models based on helpfulness and safety.
- Llama 2's model evolves through multiple stages, with reward models updated based on emerging errors.
- Rejection sampling is employed in Llama 2 to select high-reward samples during finetuning.
Margin Loss and Ranking Differences
Notably, the way responses are ranked to generate the reward model differs between InstructGPT (used by ChatGPT) and Llama 2. Llama 2 employs binary rankings and includes a "margin" label to calculate the gap between preferred and rejected responses.
RLHF Alternatives
While RLHF is a powerful approach, ongoing research aims to develop more efficient alternatives:
- Constitutional AI: This approach relies on a list of rules provided by humans, using reinforcement learning to train LLMs.
- The Wisdom of Hindsight: A relabeling-based supervised approach that outperforms RLHF on certain tasks.
- Direct Preference Optimization (DPO): An efficient alternative that directly uses the cross-entropy loss for reward model fitting.
- Reinforced Self-Training (ReST): A method that refines reward functions iteratively, achieving efficiency.
- Reinforcement Learning with AI Feedback (RLAIF): This study explores using AI-generated feedback for RLHF, potentially making training more efficient.
While RLHF remains a dominant approach, these emerging alternatives offer promising avenues for more efficient and accessible LLM training. The future of LLM development is exciting, with ongoing research pushing the boundaries of what these models can achieve. Stay tuned for more advancements in this rapidly evolving field.
We research, curate and publish daily updates from the field of AI.
Consider becoming a paying subscriber to get the latest!



