



A 'modality' refers to a particular mode or method of communication or representation. Modalities can encompass different ways in which information is presented or perceived, such as text, images, videos, audio, or any other format that conveys information.
In the context of multimodal AI systems, these models are designed to understand and generate content across various modalities, allowing them to work with diverse types of data and information sources.
NExT-GPT, is an innovative AI model that bridges the gap between various modalities.
Human Evaluation: A Unique Approach
One of the standout features of NExT-GPT is its ability to tackle complex cross-modal interactions between inputs and outputs.
Instead of relying solely on technical metrics, the researchers behind NExT-GPT engaged human evaluators to score NExT-GPT's performance on a scale from 1 to 10. This approach allowed them to gauge the model's effectiveness in handling different modalities and conversion settings.
The results were enlightening. NExT-GPT excelled in generating images but faced more challenges when dealing with videos and audio. Generating mixed combinations of multimodal content proved slightly trickier than producing single-modal content, highlighting the complexity involved in such tasks.
Example Demonstrations: The Power of NExT-GPT
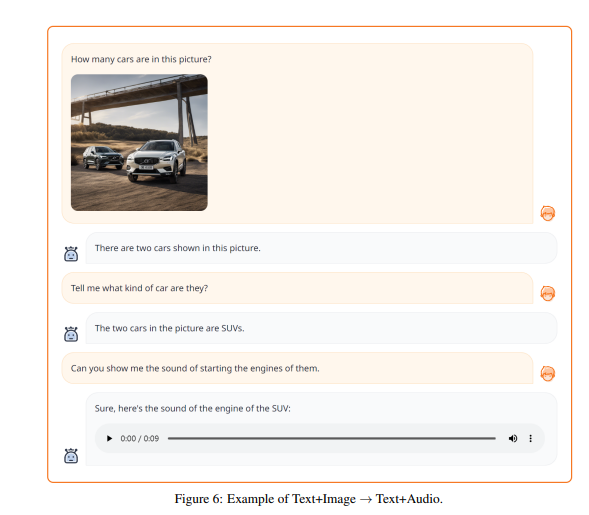
The researchers provided compelling examples showcasing how this AI model comprehends and reasons across various modalities, in any combination. These examples vividly illustrate NExT-GPT's exceptional capacity to handle complex tasks.
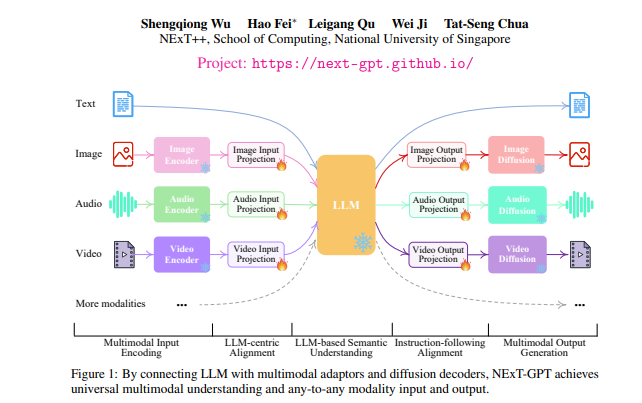
An End-to-End Multimodal Marvel
NExT-GPT is an end-to-end general-purpose multimodal Large Language Model (MM-LLM). By connecting a Language Model (LLM) with multimodal adaptors and various diffusion decoders, NExT-GPT can process inputs and generate outputs in any combination of text, images, videos, and audio. What's more, it does this with minimal additional parameters, making it cost-effective and scalable.
One key innovation in NExT-GPT is MosIT (modality-switching instruction tuning), which allows the model to seamlessly switch between different modalities based on user instructions. This, coupled with a high-quality dataset curated for MosIT, empowers NExT-GPT with complex cross-modal understanding and content generation capabilities.
Limitations and Future Prospects
While NExT-GPT represents a remarkable leap forward in multimodal AI, the journey is far from over. The researchers outline four avenues for future exploration:
- Modalities & Tasks Expansion: NExT-GPT currently supports four modalities, but the plan is to expand to include even more, such as web pages, 3D vision, heat maps, and more tasks like object detection and segmentation.
- LLM Variants: Future iterations of NExT-GPT will incorporate various LLM types and sizes, allowing users to choose the most suitable one for their specific needs.
- Multimodal Generation Strategies: The researchers are exploring the integration of retrieval-based approaches to enhance the quality of generative outputs.
- MosIT Dataset Expansion: To further enhance NExT-GPT's ability to understand and follow user prompts, the MosIT dataset will be expanded to include a more comprehensive and diverse set of instructions.
NExT-GPT is a transformative force in the domain of multimodal AI, pushing the limits of what can be achieved. As it continues to evolve and expand its capabilities, we can look forward to a future where AI systems truly understand and generate content across a wide spectrum of modalities, bringing us one step closer to achieving human-like AI systems.
We research, curate, and publish daily updates from the field of AI.
Consider becoming a paying subscriber to get the latest!



