


In the world of artificial intelligence, Large Language Models (LLMs) such as ChatGPT and Bard have revolutionized the way we interact with technology. From assisting with complex problem-solving to enhancing educational experiences, these LLMs have proven their versatility and usefulness. However, their true potential is often limited by the data they are initially trained on. While these models are adept at answering a broad range of questions, they may fall short when it comes to addressing domain-specific inquiries.
Fine-tuning involves training an LLM on custom data, allowing it to specialize in a particular task or domain. This process involves updating the model's parameters using a smaller dataset tailored for the target task, thereby honing its abilities and making it more reliable.
One illustrative example where fine-tuning is indispensable is obtaining a medical diagnosis from raw medical records, such as electronic health records or medical imaging reports. A generic LLM like ChatGPT might not be well-equipped for this task, lacking specialized medical knowledge and experience with real medical cases. Fine-tuning the model on validated, trusted medical data is vital to ensure precise and dependable results, enabling the LLM to provide accurate diagnoses.
The Pedigree of Fine-Tuning
The concept of fine-tuning has a rich research history, dating back to influential papers published in 2018. The first paper, "Improving Language Understanding by Generative Pre-Training" by Radford et al. [2], introduced the GPT model used in ChatGPT. It showcased how fine-tuning the model on specific datasets allowed it to achieve state-of-the-art results across multiple tasks.
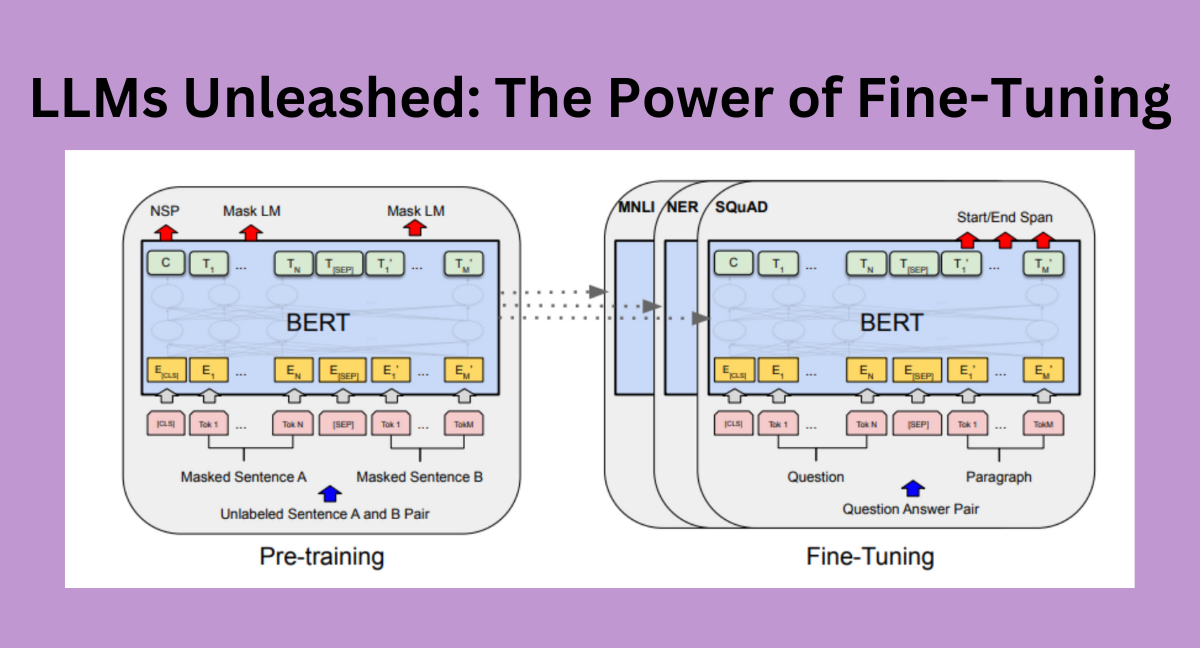
Similarly, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" by Devlin et al. [3] presented BERT, a groundbreaking transformer model. The paper demonstrated BERT's capacity for fine-tuning, enabling it to excel in various tasks after adaptation. This paved the way for domain-specific fine-tuning, as shown in the image below, where BERT can be fine-tuned on specific tasks such as SQuAD.
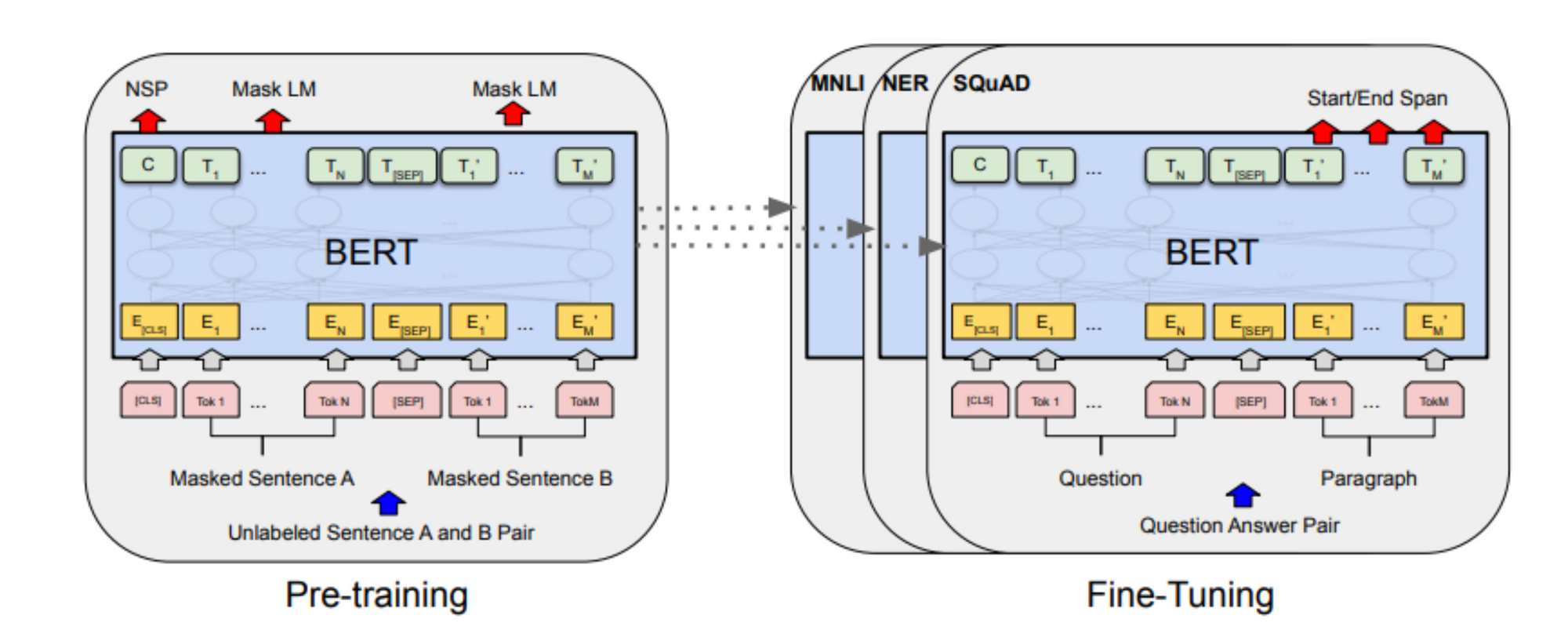
Source: Image from BERT paper
Fine-Tuning vs. Prompting
Both fine-tuning and prompting are valuable approaches to leveraging LLMs for different tasks. Fine-tuning involves updating the model's parameters using a labelled dataset, and tailoring it for the specific task. On the other hand, prompting involves providing specific instructions or text as prompts to a generalized LLM to guide its response.
For complex tasks that require accurate and trustworthy output, fine-tuning is often the better choice. Fine-tuned models, armed with domain-specific knowledge, outperform prompted models on intricate tasks, as demonstrated in the GPT-3 paper [4]. However, fine-tuning can be computationally cheaper for inference, as it requires minimal explicit instructions during prediction.
On the other hand, prompting shines when simplicity and speed are essential. It allows users to quickly iterate on tasks without the need to retrain the model every time they update the prompt or change the dataset. Additionally, prompting doesn't rely on labeled data, making it an attractive option for scenarios with limited training examples.

Source:Image from GPT-3 paper
Steps to Fine-Tune a Model
The fine-tuning process involves several crucial steps that developers must follow to unleash the full potential of an LLM:
- Define Task and Dataset: Identify the specific task you want the LLM to excel at and curate the relevant dataset for fine-tuning.
- Select LLM Architecture: Choose the appropriate LLM architecture that aligns with your task requirements.
- Update Model Weights: Fine-tune the model's parameters using the custom dataset, enabling it to specialize in the target task.
- Select Hyperparameters: Fine-tuning involves tuning hyperparameters to optimize the model's performance on the target task.
- Evaluate Model: Rigorously assess the fine-tuned model's performance and accuracy to ensure its reliability.
- Deploy Model: Once the fine-tuning process is complete and the model meets the desired standards, deploy it for real-world use.
Fine-Tuning with Terra-Cotta.ai
OpenAI offers fine-tuning support for their GPT-3 models, empowering developers to train these models on their custom data. Terra-Cotta.ai, a free platform, simplifies the fine-tuning process by guiding users through the necessary steps to fine-tune OpenAI LLMs. The platform also facilitates comparisons between fine-tuned and prompted models, enabling developers to choose the most suitable approach for their use cases.
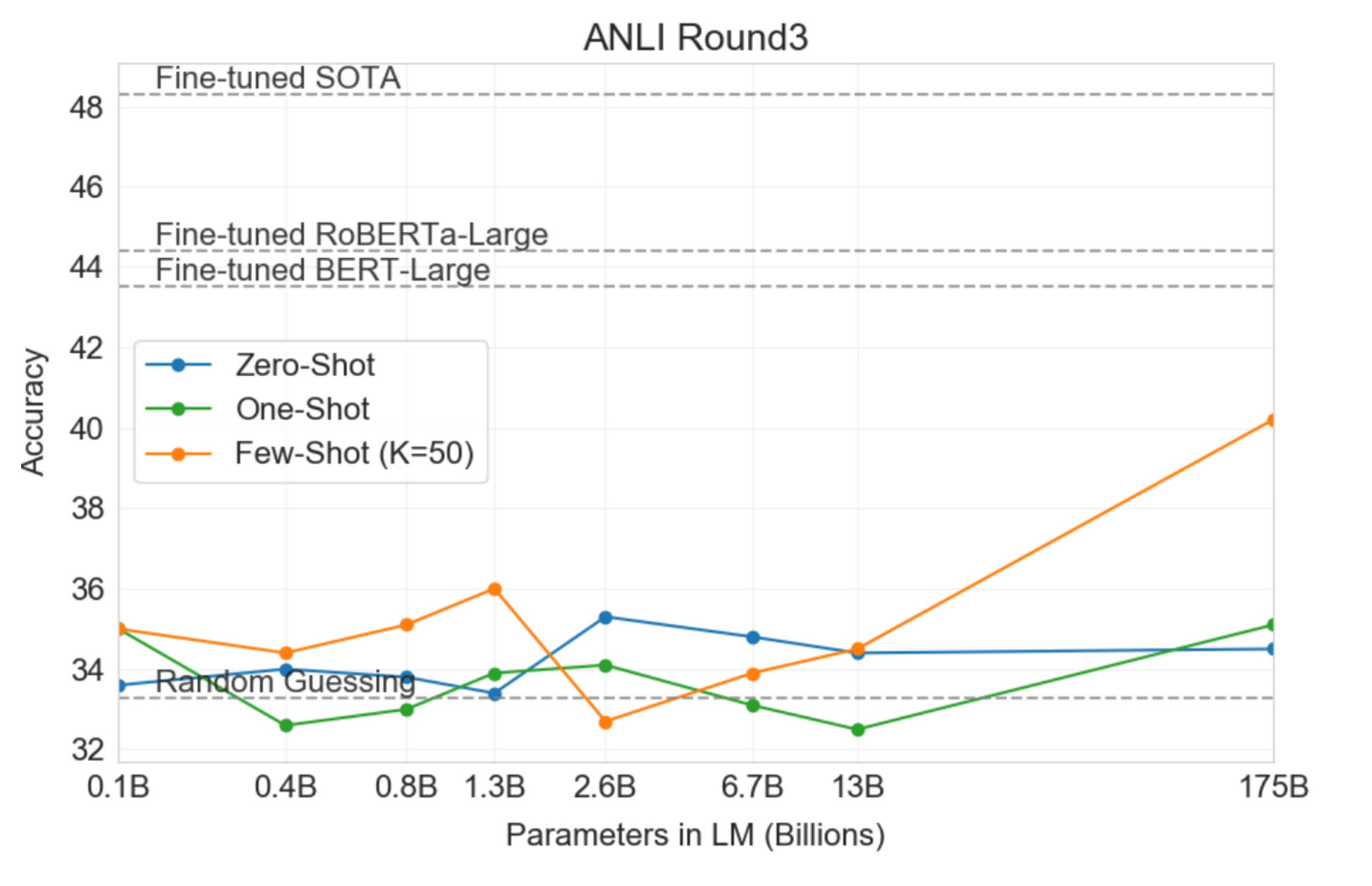
Source: Image from GPT-3 paper
The power of fine-tuning is undeniable, as it allows developers to harness the vast knowledge and capabilities of pre-trained LLMs while tailoring them to solve real-world tasks effectively. Fine-tuning not only improves the accuracy of LLMs but also proves to be cost-effective in the long run, especially for complex tasks. On the other hand, prompting offers a swift and efficient solution for simpler tasks or scenarios with limited training data.
As the field of natural language processing continues to evolve, fine-tuning remains a crucial technique in pushing the boundaries of what LLMs can achieve. So, whether you're seeking precise medical diagnoses or enhancing language understanding for your specific domain, fine-tuning is the key to unlocking the full potential of LLMs and revolutionizing the way we interact with AI.
Reference Links:
https://arxiv.org/pdf/2305.14552v1.pdf
https://arxiv.org/pdf/1810.04805.pdf
https://arxiv.org/pdf/2005.14165.pdf
We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!



