




Huber loss is a loss function that is commonly used in regression problems to balance the effects of outliers and inliers in the data. Unlike the mean squared error (MSE) loss, which treats all errors equally, the Huber loss gives less weight to large errors, making it more robust to outliers.
In this blog post, will explain what Huber loss is, how it works, and how it compares to other loss functions commonly used in regression.
What is Huber Loss?
The Huber loss function is defined as:
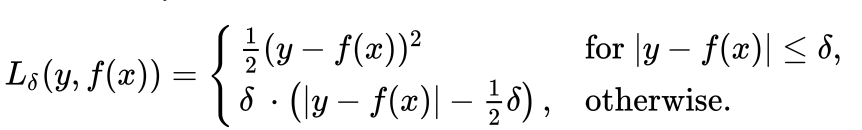
where y is the true value, f(x) is the predicted value, and delta is a hyperparameter that controls the threshold between the quadratic and linear regions of the loss function.
The Huber loss is a piecewise function that is quadratic for small errors (|y - f(x)| <= delta) and linear for large errors (|y - f(x)| > delta). The quadratic region is the same as the MSE loss, while the linear region is like the absolute error (L1) loss.
How does Huber Loss work?
The Huber loss function is a compromise between the MSE and L1 loss functions. Like the MSE loss, it penalizes large errors more than small errors, but like the L1 loss, it is less sensitive to outliers than the MSE loss.
By choosing an appropriate value for delta, we can control the balance between the quadratic and linear regions of the loss function. For small values of delta, the Huber loss behaves like the MSE loss and is more sensitive to outliers. For large values of delta, the Huber loss behaves like the L1 loss and is less sensitive to outliers.
Advantages of Huber Loss
The Huber loss function has several advantages over other loss functions commonly used in regression problems:
- Robustness to outliers: The Huber loss is less sensitive to outliers than the MSE loss, which means that it can give more accurate predictions when the data contains outliers.
- Continuous and differentiable: The Huber loss is continuous and differentiable, which makes it easier to use in optimization algorithms that require gradient information.
- Adjustable sensitivity: The Huber loss allows us to adjust the sensitivity to outliers by choosing an appropriate value for the
deltahyperparameter.
Disadvantages of Huber Loss
While the Huber loss is a useful loss function for regression problems, it does have some disadvantages:
- Non-convexity: The Huber loss is non-convex, which means that there can be multiple local minima that optimization algorithms may get stuck in.
- Tuning hyperparameters: The Huber loss requires tuning the
deltahyperparameter, which can be time-consuming and may require cross-validation to find the best value.
Comparison with other Loss Functions
Here's a comparison of the Huber loss with other commonly used loss functions in regression:
- Mean squared error (MSE): The MSE loss is sensitive to outliers and penalizes large errors more than small errors. It is the most commonly used loss function in regression problems.
- Mean absolute error (MAE): The MAE loss is less sensitive to outliers than the MSE loss, but it treats all errors equally regardless of their size.
- L1 loss: The L1 loss is similar to the Huber loss in that it is less sensitive to outliers than the MSE loss.
We research, curate and publish daily updates from the field of AI.
Consider becoming a paying subscriber to get the latest!



