




If you like our work, please consider supporting us so we can keep doing what we do. And as a current subscriber, enjoy this nice discount!
Also: if you haven’t yet, follow us on Twitter, TikTok, or YouTube!
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
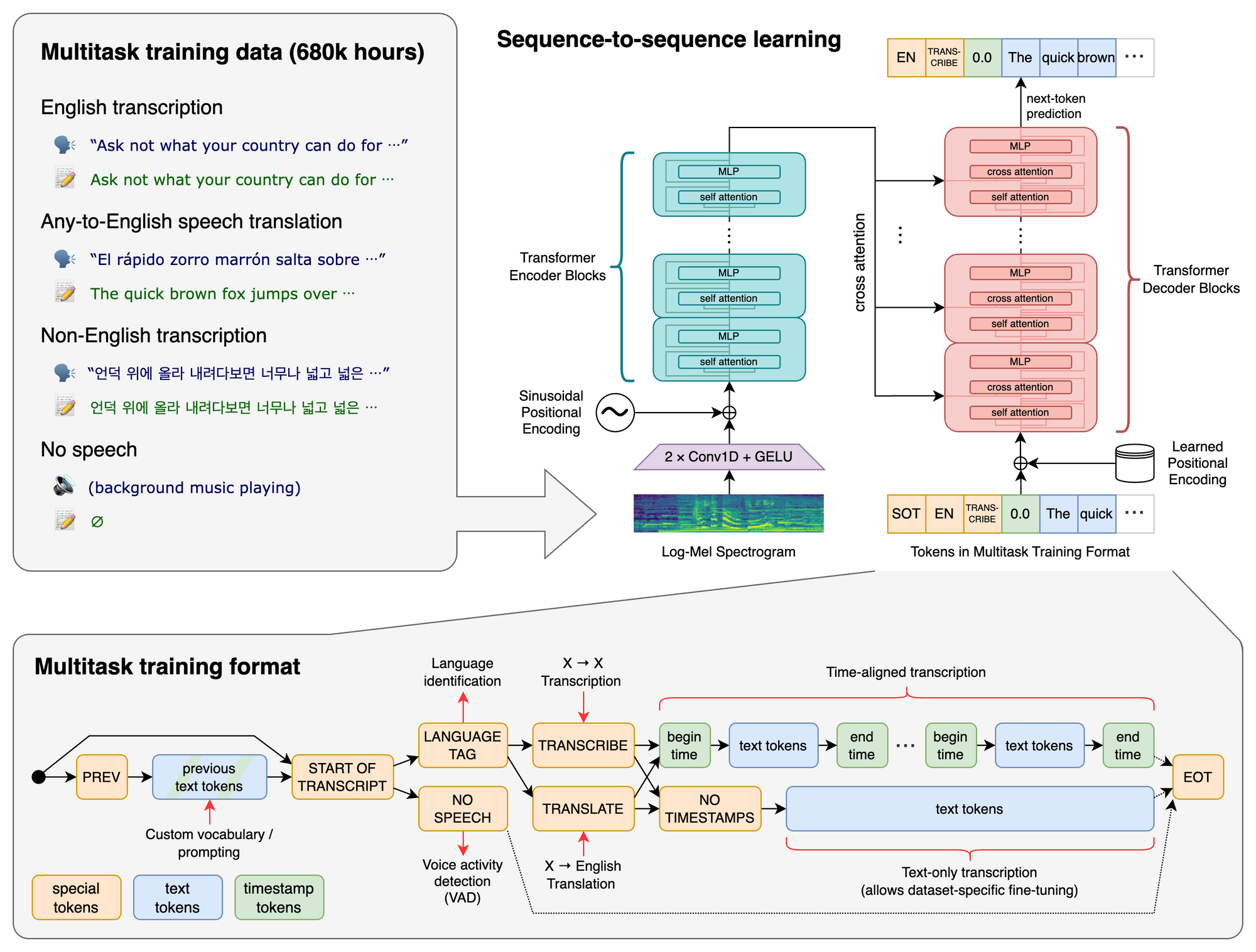
The Transformer sequence-to-sequence model is trained on different speech processing tasks, such as multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. As a result, all of these tasks can be represented together as a sequence of tokens which can be predicted by the decoder, thereby replacing a number of different stages within a traditional speech processing pipeline by a single model. A set of special tokens serves as task specifiers or classification targets in the multitask training format.
Explore more here:
 openai
openaiDo you like our work?
Consider becoming a paying subscriber to support us!



