




The Eve of Discovery
On the eve of the Christmas holidays, the university lecture hall buzzed with anticipation. Dr. Silverman, a renowned figure in the field of AI, was about to demystify the complexities of transformer architecture to a room full of aspiring students.
"Welcome, everyone," Dr. Silverman began, his voice echoing in the hall decked with festive decorations. "Today, we'll explore the transformer architecture, an innovation as vast and intricate as an Infinite Library."
The Structure of the Infinite Library
"The transformer model," he continued, "is akin to a library with two main sections: the Encoder and the Decoder. The Encoder's job is like cataloging information, breaking down sentences into tokens - individual units of meaning and embedding them. It's similar to a librarian categorizing books for easy retrieval."
A hand shot up in the front row. "Professor, how do these embedding work?"
"Good question," Dr. Silverman responded. "Consider each word in a sentence as a book in our library. Embedding is the process of assigning a unique identifier to each book, making them easier to find later."
Decoding the Encoder
As he delved deeper, another student inquired, "What makes the Encoder so special in this library?"
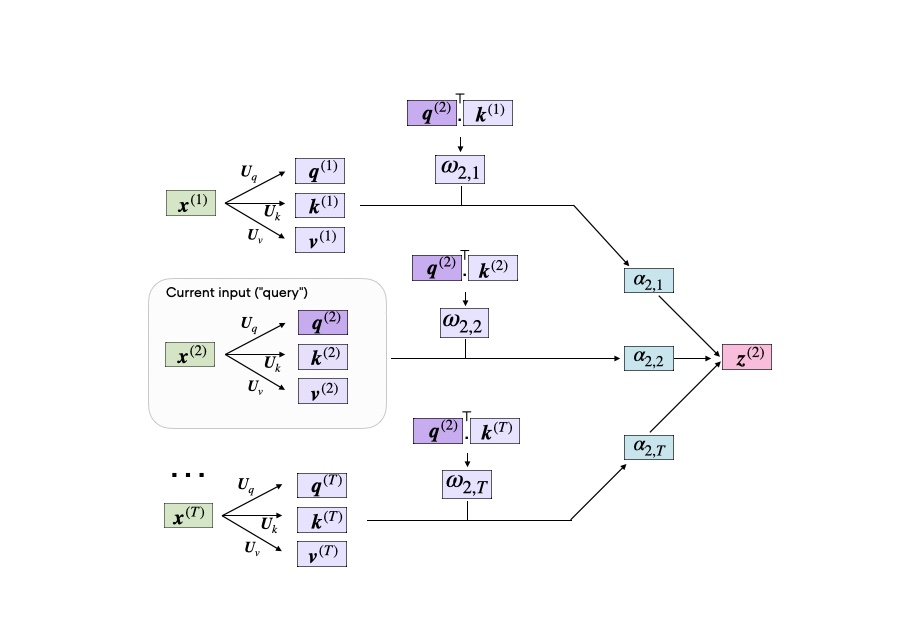
"The Encoder uses self-attention mechanisms," Dr. Silverman explained. "Imagine walking into a library and whispering your topic of interest. The librarian (the Encoder) not only hears you but also understands the context of your request. The self-attention mechanism allows the Encoder to weigh the importance of each word in relation to others in the sentence. Attention-based mechanism completely transformed the working of neural machine translations while exploring contextual relations in sequences! The encoder in this system processes the input sequence and compresses all the important information into a smaller form, known as internal state vectors or a context vector, or hidden state. The purpose of the context vector is to hold all the crucial details from the input, which helps the decoder in making accurate predictions. This crucial information, including the hidden and cell state of the network, is then forwarded to the decoder as its input."
The Decoder's Tale
Dr. Silverman then shifted focus to the Decoder. "The Decoder, on the other hand, is like a seeker in the library. It takes the organized context (hidden state) from the Encoder and begins to construct a response, piece by piece, word by word. It predicts the next word in a sequence, akin to predicting the next book you'd need based on your previous selections."
"However", said Dr. Silverman, "It has its's own drawbacks too. A basic sequence-to-sequence (seq2seq) model like one we are discussing struggles to understand complex relationships in long sentences. This means if there are important connections or context in parts of a long text, the model might not pick up on them. As a result, this can lower the model's performance and accuracy."
Attention – The Heart of the Library
A student from the back raised a hand, "Professor, is this where attention mechanism fit into this?"
"Yes! " he replied. "The attention mechanism is what guides the Encoder and Decoder. It's like having a guide in the library who knows which books (or words) are most relevant for your topic. This mechanism helps the model focus on relevant parts of the input, enhancing the accuracy of the output."
"The basic idea involves improving the typical encoder-decoder structure used in processing text. Instead of relying on a fixed, short internal representation, this approach saves important intermediate outputs from the encoder's LSTM network at each step of the input sequence. The model is also trained to focus selectively on these key intermediate elements. It then connects these elements to corresponding parts in the output sequence, enhancing the model's accuracy and relevance in handling text data."
"However", said Dr. Silverman, "this idea though highly effective, is also power hungry".
Examples Bring Clarity
Dr. Silverman used analogies like finding a needle in a haystack or searching for a favorite chapter in a book to illustrate the concept of 'positional encoding' and 'multi-head attention.'
"As you sift through a book for a favorite chapter, you remember its position - early, middle, or late. That's what positional encoding in the transformer model does. It helps the model understand where each word falls in a sentence."
However he left the topic to be covered in detail in his next lecture.
The Lecture's Resonance
As the lecture concluded, the students' faces glowed with understanding. Dr. Silverman's ability to distill complex concepts like multi-head attention and feed-forward networks into relatable examples had opened a new world of understanding.
"The realm of transformer architecture is expansive," Dr. Silverman concluded, "much like our Infinite Library, full of knowledge and waiting to be explored. Remember, each discovery leads to another, especially in the world of AI."
The students left, their minds abuzz with newfound knowledge and a desire to explore further. The lecture had not only been an enlightening journey through the transformer architecture but also a testament to the power of curiosity and learning.
Recommended Series:

Enjoyed unraveling the mysteries of AI with Everyday Stories? Share this gem with friends and family who'd love a jargon-free journey into the world of artificial intelligence!




