



In recent months, chatbots have gained significant traction with the development and release of several models, including ChatGPT, and Bard. The user experience of these chatbots is a hot topic, particularly in the context of open access and open-source alternatives.
While there are several open-source frameworks available for training chatbot models using two training paradigms - instruction finetuning and reinforcement learning through human feedback (RLHF) - most models do not apply both paradigms. This is because RLHF training is complex and challenging to implement. However, Open Assistant, Anthropic, and Stanford have recently made chat RLHF datasets accessible to the public. These datasets, along with the straightforward training of RLHF provided by trlX, are the backbone for the first large-scale instruction finetuned and RLHF model - StableVicuna.
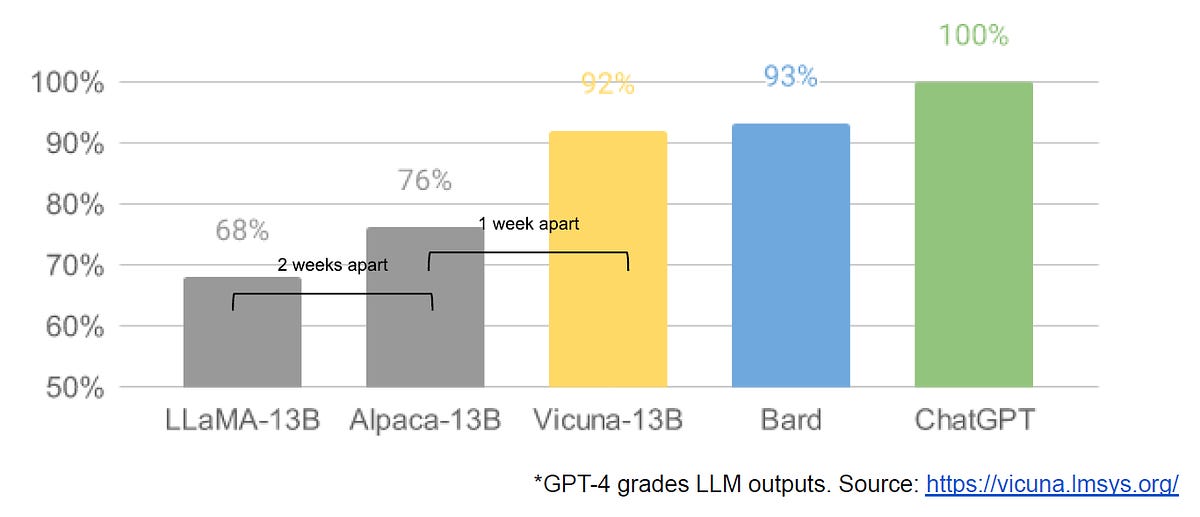
StableVicuna is the first large-scale open-source chatbot trained via RLHF. It is an instruction-finetuned and RLHF-trained version of Vicuna v0 13b, which is an instruction-finetuned LLaMA 13b model. StableVicuna's performance is impressive, and it outperforms other similarly sized open-source chatbots.
To achieve StableVicuna's strong performance, we use the base Vicuna model and follow the typical three-stage RLHF pipeline outlined by Steinnon et al. and Ouyang et al. The model is further trained using a mixture of three datasets - OpenAssistant Conversations Dataset (OASST1), GPT4All Prompt Generations, and Alpaca - and trlx to train a reward model. Finally, we use trlX to perform Proximal Policy Optimization (PPO) reinforcement learning to perform RLHF training of the SFT model to arrive at StableVicuna.
StableVicuna is available on the HuggingFace Hub and can be downloaded as a weight delta against the original LLaMA model. The model is in the final stages of development, and alongside it, a chat interface is also in the works. The team is committed to continuous improvement and encourages users to try StableVicuna and provide feedback to enhance the user experience.
Read more:
 Anel Islamovic
Anel Islamovic
While we are discussing open source, you do not want to miss the note thats doing the rounds in the news.
We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!



