


Large language models have revolutionized natural language processing tasks in recent years, enabling impressive performance in tasks like language modeling, text generation, and question-answering. However, these models come with their challenges, such as high memory consumption and inefficient inference. In response, a new foundational architecture called Retentive Network (RetNet) has been proposed.
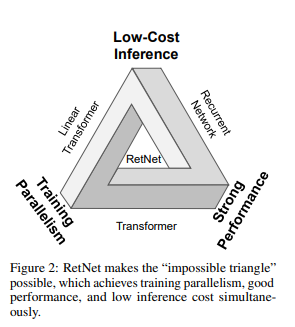
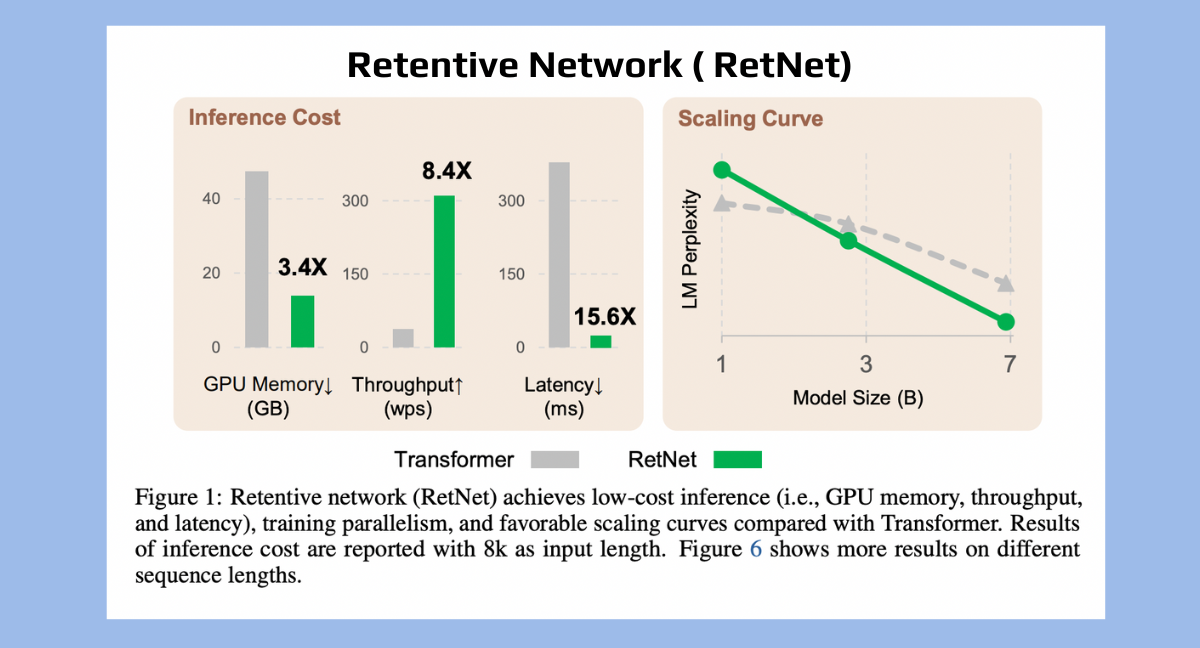
RetNet is designed to address the limitations of traditional Transformer-based language models. It offers several key advantages, including training parallelism, cost-effective inference, and high performance. It achieves this through a retention mechanism for sequence modeling, which enhances decoding throughput, latency, GPU memory, and long-sequence modeling efficiency.
The theoretical underpinning of RetNet connects recurrence and attention. The retention mechanism supports three computation paradigms: parallel, recurrent, and chunkwise recurrent representations. The parallel representation enables efficient training parallelism. The recurrent representation allows for low-cost O(1) inference, improving decoding throughput, latency, and GPU memory without sacrificing performance. The chunkwise recurrent representation facilitates efficient long-sequence modeling with linear complexity.
Experimental results on language modeling show that RetNet offers favorable scaling results, parallel training, low-cost deployment, and efficient inference. The architecture outperforms traditional Transformers for model sizes larger than 2 billion parameters. It also exhibits good performance on zero-shot and few-shot learning tasks.
The benefits of RetNet are further evident in terms of training and inference costs. Compared to Transformer and other variants, RetNet is more memory-efficient and has higher throughput during training. During inference, RetNet outperforms Transformers in memory consumption, throughput, and latency.
RetNet is a strong successor to traditional Transformers for large language models. Its retention mechanism and multi-scale representations offer an efficient, high-performance architecture that overcomes the limitations of existing models. With RetNet, researchers and developers can build powerful language models with improved training and inference efficiency.
Read More: https://arxiv.org/pdf/2307.08621.pdf
Video:https://www.youtube.com/watch?v=C6Hi5UkXJhs
We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!



