




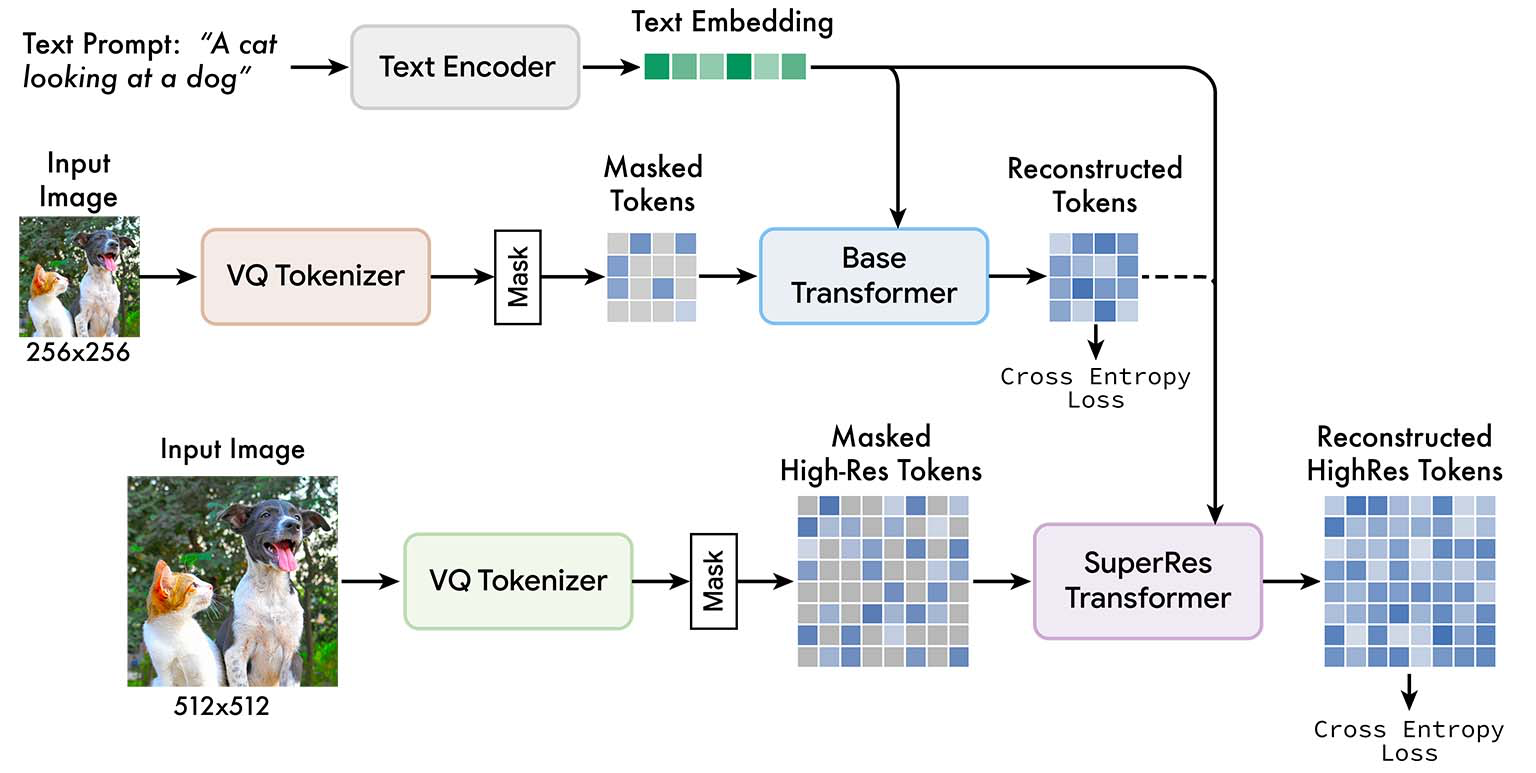
Muse is a machine learning model that is able to generate images based on text input. It is trained on a task where it is given the text embedding (a mathematical representation of the meaning of a piece of text) from a large language model (a machine learning model that is trained to understand and generate human-like text) and is asked to predict certain randomly masked parts of an image.
Muse is able to generate high-quality images because it is trained on a large language model that has a fine-grained understanding of language and is able to understand visual concepts such as objects, their spatial relationships, and more. Muse is more efficient than other models (called diffusion models or autoregressive models) because it uses discrete tokens (a way of representing information using a limited set of symbols) and requires fewer steps to generate images because it is able to generate images in parallel.
Muse is able to achieve state-of-the-art performance (meaning it is one of the best models available) on a dataset called CC3M and can generate high-quality images on the COCO dataset without any additional training.
Muse can also be used to edit images in various ways, such as filling in missing parts of an image or adding new elements to it. An example from their website is as follows:


Architecture
Read More:
We curate and publish daily updates from the field of AI.
Consider becoming a paying subscriber to get the latest!