



Introduction:
Large language models (LLMs) have revolutionized various industries, but their accessibility for non-industry researchers has been limited. To bridge this gap, MosaicML is proud to present MPT-7B, the latest addition to the MosaicML Foundation Series. MPT-7B is an open-source, commercially-usable transformer model that matches and surpasses the quality of LLaMA-7B. Let's explore the features and benefits of MPT-7B in simplified points:
Unprecedented Scale and Training:
MPT-7B was trained from scratch on an astounding 1 trillion tokens of text and code, making it one of the largest models available.
The training process was completely automated, requiring zero human intervention, and completed in just 9.5 days.
The cost of training MPT-7B amounted to approximately $200,000.
Commercial Usability and Open-Source Nature:
MPT-7B is open source, enabling researchers and developers to utilize it for various applications.
Unlike LLaMA, MPT-7B is licensed for commercial use, making it suitable for a wide range of projects.
Improved Data Training Capacity:
MPT-7B offers a substantial improvement in data training capacity compared to other open-source LLMs.
Trained on 1T tokens, MPT-7B surpasses the training corpus size of Pythia, OpenLLaMA, and StableLM.
This extensive training enhances the model's understanding of text and code, leading to improved performance.
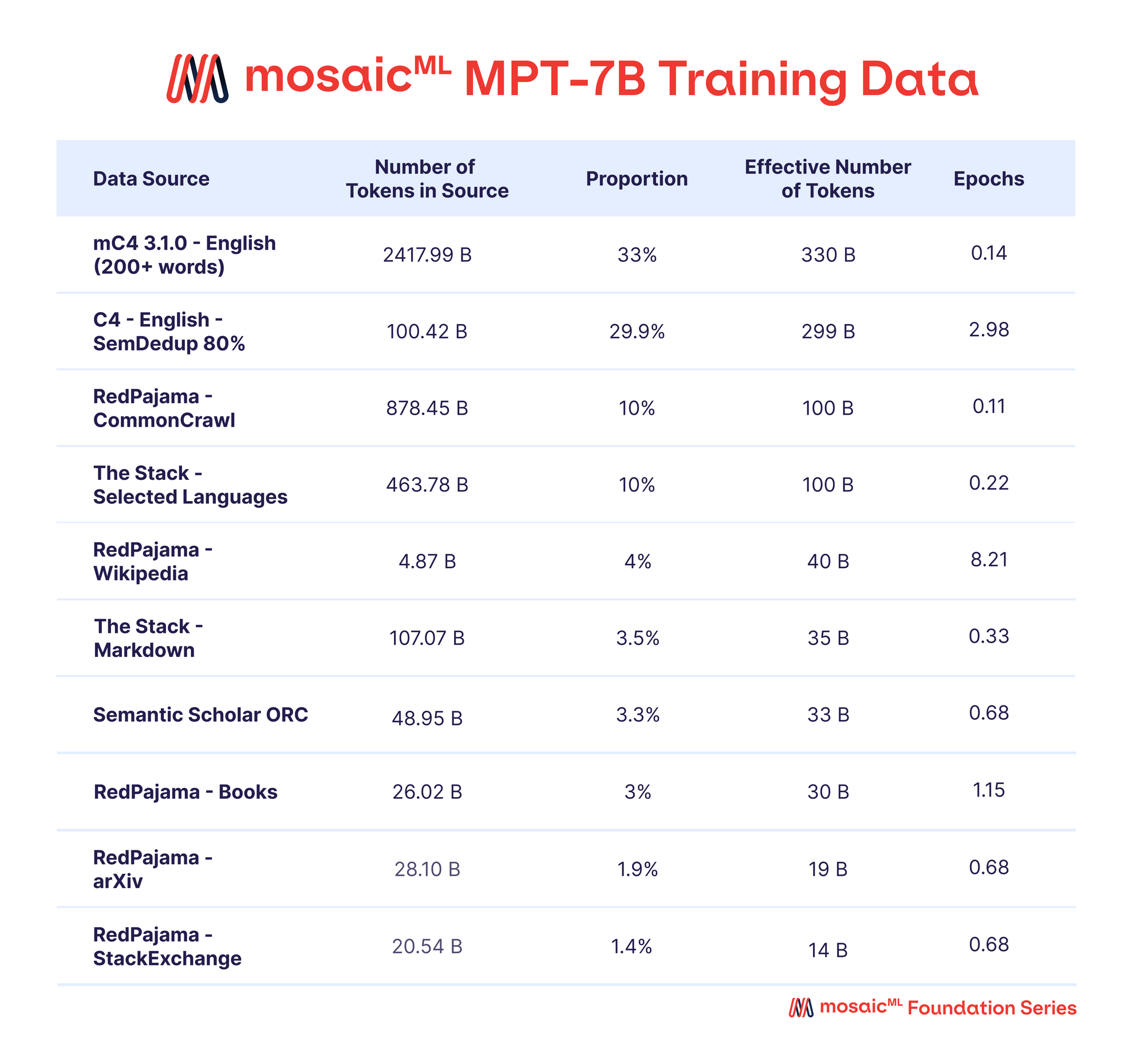
Table 2 - Data mix for MPT-7B pretraining.
A mix of data from ten different open-source text corpora. The text was tokenized using the EleutherAI GPT-NeoX-20B tokenizer, and the model was pre-trained on 1T tokens sampled according to this mix.
Handling Long Inputs:
MPT-7B leverages ALiBi, a technique that enables it to handle inputs of exceptional length.
While other models struggle with inputs ranging from 2,000 to 4,000 tokens, MPT-7B can handle inputs up to 84,000 tokens.
The context length of MPT-7B-StoryWriter-65k+ reaches an impressive 65,000 tokens, offering unprecedented capabilities.
Optimized for Efficiency:
MPT-7B incorporates FlashAttention and FasterTransformer to optimize both training and inference speed.
These optimizations allow for faster model training and efficient real-time response during inference.
Base Model and Finetuned Variants:
MosaicML provides the base MPT-7B model, a decoder-style transformer with 6.7 billion parameters.
The model was trained on a curated dataset of 1T tokens of text and code, prepared by MosaicML's data team.
FlashAttention and ALiBi are integrated into the base model, enhancing training speed and allowing for finetuning and extrapolation.
Finetuned Variants:
In addition to the base model, MosaicML offers three finetuned variants to demonstrate the versatility of MPT-7B.MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+ showcase different applications of the base model.
Researchers and developers can use these variants as a starting point for their projects.
- MPT-7B-StoryWriter-65k+ is a model designed for reading and writing stories with extremely long context lengths, up to 65k tokens.
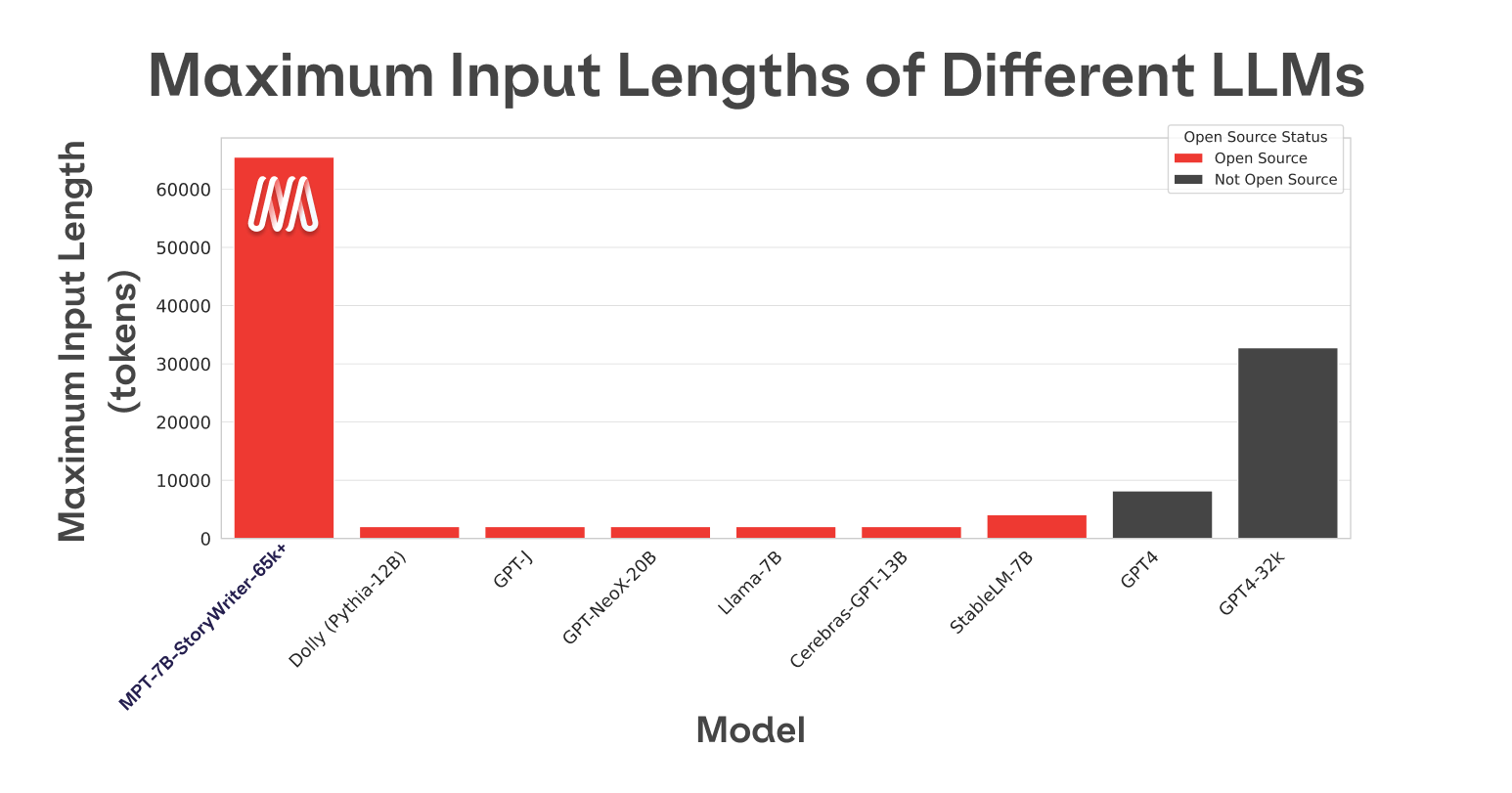
- (Figure 1 - Training context length of MPT-7B-StoryWriter-65k+ vs. other models.
The longest context length of any other open-source model is 4k. GPT-4 has a context length of 8k, and another variant of the model has a context length of 32k.) - It was built by finetuning MPT-7B on a filtered fiction subset of the books3 dataset, using ALiBi to handle context length adaptation.
- MPT-7B-StoryWriter-65k+ can extrapolate even beyond 65k tokens, with demonstrated generations as long as 84k tokens.
- MosaicML has open-sourced the entire codebase for pretraining, finetuning, and evaluating MPT, along with the model checkpoints.
- MPT-7B-Instruct is a model focused on short-form instruction following, trained on a dataset derived from Databricks Dolly-15k and Anthropic's Helpful and Harmless datasets.
- MPT-7B-Chat is a chatbot-like model for dialogue generation, trained on multiple datasets including ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, and Evol-Instruct.
- MPT models, including MPT-7B, have several improvements in performance-optimized layer implementations, training stability, and elimination of context length limits through ALiBi.
- MPT-7B matches the quality of LLaMA-7B and outperforms other open-source models on standard academic tasks, as evaluated through multiple benchmarks.
- MPT-7B-StoryWriter-65k+ enables handling extremely long sequences, surpassing the context length capabilities of other models in the open-source community.
- MPT-7B-Instruct provides a commercially-usable instruction-following variant, trained on a curated dataset augmented with Anthropic's Helpful & Harmless dataset.
- MPT-7B-Chat offers a conversational version of MPT-7B, fine-tuned on multiple datasets, providing seamless multi-turn interactions.
- The MosaicML platform was used to build these models, showcasing the efficiency, ease of use, and rigorous attention to detail offered by the platform.
- The data for MPT-7B pretraining was a curated mix from various sources, emphasizing English natural language text and including up-to-date information from 2023.
- EleutherAI's GPT-NeoX 20B tokenizer was used, offering desirable characteristics for tokenizing code and providing consistent space delimitation.
- MosaicML's StreamingDataset was utilized to efficiently stream data during training, eliminating the need to download the entire dataset and allowing easy resumption of training.
These points provide a simplified overview of the different MPT models, their capabilities, and the process of building them on the MosaicML platform.
Tokenizer: To tokenize the code, EleutherAI's GPT-NeoX 20B tokenizer was utilized. This tokenizer utilizes byte-pair encoding (BPE) and offers several beneficial features tailored for code tokenization. Some notable features include:
- Trained on a diverse dataset, including code (referred to as The Pile).
- Consistent space delimitation, unlike the GPT2 tokenizer that tokenizes inconsistently based on prefix spaces.
- Tokens for repeated space characters, enabling efficient compression of text with repeated space characters.
The tokenizer's vocabulary size is 50257, but we set the model's vocabulary size to 50432. This decision served two purposes. First, it made the vocabulary size a multiple of 128, resulting in an observed improvement of up to four percentage points in initial experiments regarding the most frequent update (MFU). Second, it reserved additional tokens for future UL2 training.
Efficient Data Streaming:
To facilitate training, MosaicML's StreamingDataset offers several benefits:
Eliminates the need to download the entire dataset before commencing training.
Enables seamless resumption of training from any point within the dataset. A paused run can be resumed without having to fast-forward the data loader from the beginning.
Guarantees deterministic sample reading order, irrespective of the number of GPUs, nodes, or CPU workers involved.
Allows easy mixing of data sources by specifying desired proportions and enumerating the data sources. StreamingDataset takes care of the rest, making it effortless to conduct preparatory experiments with different data combinations.
For more detailed information, you can refer to the StreamingDataset blog.
Training Compute:
All MPT-7B models were trained on the MosaicML platform, utilizing the following tools:
Compute Oracle Cloud's A100-40GB and A100-80GB GPUs.
Orchestration and Fault Tolerance: MCLI and the MosaicML platform.
Data: OCI Object Storage and StreamingDataset.
Training software: Composer, PyTorch FSDP, and LLM Foundry.
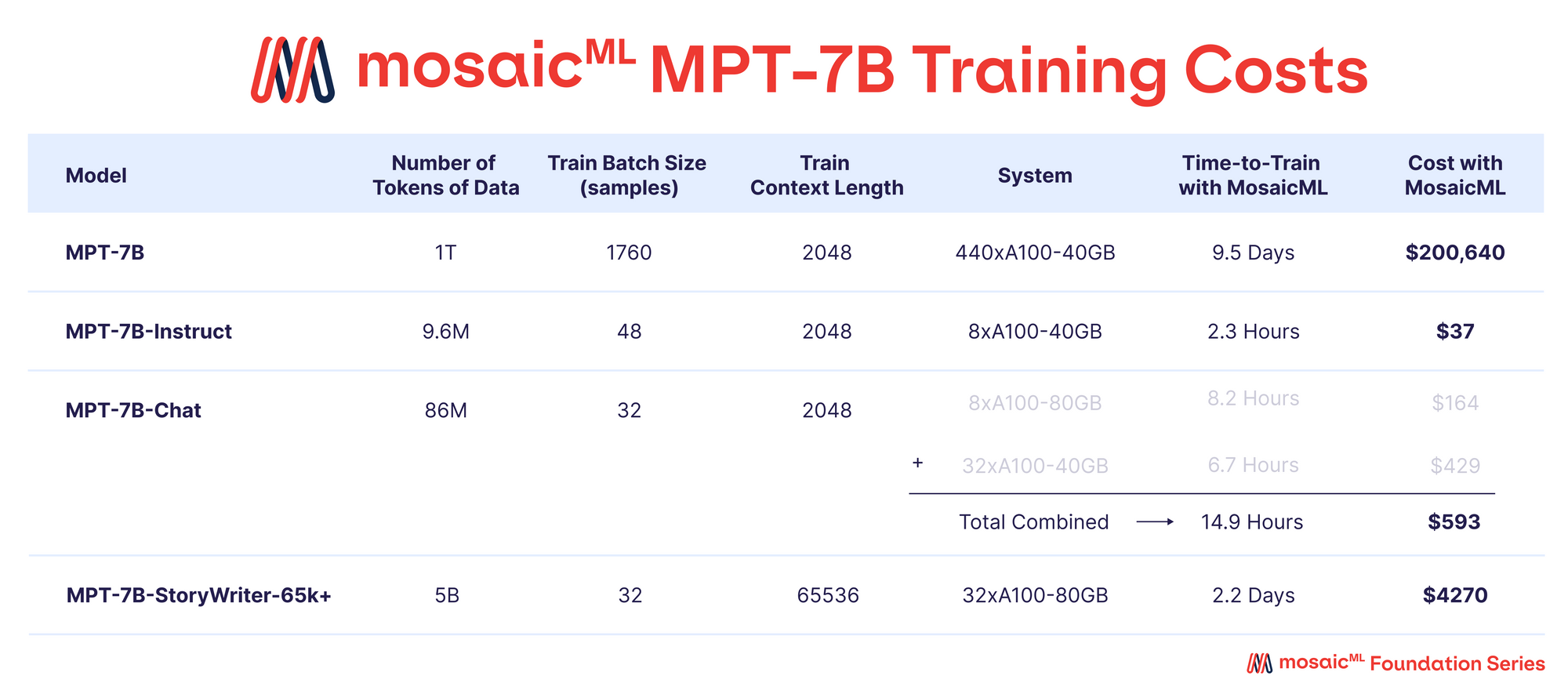
Table 3 - Training details for each of our MPT-7B models.
Time to Train’ is the total runtime from job start to finish, including checkpointing, periodic evaluation, restarts, etc. ‘Cost’ is computed with pricing of $2/A100-40GB/hr and $2.50/A100-80GB/hr for reserved GPUs on the MosaicML platform.
Table 3 highlights that the majority of the training resources were allocated to the base MPT-7B model. This model required approximately 9.5 days to train on 440xA100-40GB GPUs, with a cost of approximately $200k. In comparison, the fine-tuned models demanded significantly less computing power and were much more cost-effective, ranging from a few hundred to a few thousand dollars each.
Training Stability: Training LLMs with billions of parameters on hundreds to thousands of GPUs presents significant challenges. Hardware failures and loss spikes can disrupt the training process, requiring constant monitoring and manual interventions. Convergence stability was addressed through architecture and optimization improvements. ALiBi was used instead of positional embeddings to enhance resilience against loss spikes. The Lion optimizer replaced AdamW, providing stable update magnitudes and reducing optimizer state memory. The MosaicML platform's NodeDoctor feature monitored and resolved hardware failures, while the JobMonitor feature resumed training after such failures automatically.
Inference:
MPT is designed to enable fast, easy, and cost-effective deployment for inference. MPT models are fully compatible with the HuggingFace ecosystem, allowing seamless integration with tools like the HuggingFace Hub and standard pipelines such as model. generate(...). With optimized layers like FlashAttention and low precision layer norm, MPT-7B outperforms other 7B models like LLaMa-7B, making it suitable for creating efficient inference pipelines using HuggingFace and PyTorch. For even better performance, MPT weights can be directly ported to FasterTransformer or ONNX using the provided scripts and instructions. Deploying MPT models on MosaicML's Inference service ensures an optimal hosting experience with managed endpoints and custom model endpoints for cost efficiency and data privacy.
What's Next?
The release of MPT-7B marks the culmination of two years of work at MosaicML, focusing on building and battle-testing open-source software (Composer, StreamingDataset, LLM Foundry) and proprietary infrastructure (MosaicML Training and Inference). MPT, the MosaicML LLM Foundry, and the MosaicML platform provide a solid foundation for building custom LLMs for private, commercial, and community use. The community's creativity and innovation using these tools and artifacts are eagerly anticipated.
Importantly, the MPT-7B models are just the beginning. MosaicML is committed to producing higher-quality foundation models to address more challenging tasks and enhance product development. Exciting follow-on models are already in training, and there will be more updates on them soon!
We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!
Read More:

.png)



