




Introduction
Recently, there has been a growing debate about the use of large language models (LLMs) and tools like ChatGPT in schools. Some people have argued that LLMs should be banned in schools due to concerns about privacy, ethics, and the potential negative impact on education.
There are several reasons for the controversy surrounding the use of LLMs in schools. One major concern is the potential for privacy violations, as LLMs are capable of processing large amounts of sensitive personal data. Additionally, some people have raised ethical concerns about the use of LLMs for automated grading and other tasks that could impact students' futures.
While there are valid concerns about the use of LLMs in schools, there are also compelling arguments in favor of their use. For example, LLMs can provide students with access to vast amounts of information and can help to speed up research efforts. Additionally, they can help to foster creativity and innovation in the classroom.
The use of LLMs in schools is an important issue that deserves careful consideration and discussion. By balancing the benefits and concerns, educators and researchers can make informed decisions about the best way to use these tools in the classroom.
Before we discuss in detail the aspects of the controversy and I share my viewpoint, Let’s understand the benefits of using LLMs.
Speed and efficiency: One of the primary benefits of using large language models is that they can significantly speed up research efforts. LLMs can process large amounts of data and generate insights in real time, which can help researchers save time and resources. Additionally, tools like ChatGPT can be used to automate routine tasks and support more complex research projects.
Improved accuracy: Another key benefit of using LLMs is that they can lead to more accurate research outcomes. LLMs are trained on massive amounts of data and can perform complex natural language processing tasks with high accuracy. This can help researchers to generate more reliable insights and avoid errors that can occur with manual data processing.
Increased creativity and innovation: Using LLMs can also help foster research creativity and innovation. LLMs can be used to generate new ideas, support hypothesis testing, and explore novel research directions. Additionally, LLMs can help researchers to tackle complex problems that would be difficult to solve using traditional methods.
Applications in various domains: LLMs and tools like ChatGPT have a wide range of applications and can be used to support research in various domains, including natural language processing, machine learning, computer vision, and more. By leveraging the power of LLMs, researchers can tackle complex problems and make important advances in these areas.
Purpose of the blog:
In this blog, we will be exploring the use of large language models (LLMs) and tools like ChatGPT in fostering education and research, with a focus on chaos theory. Over the past few years, LLMs have become increasingly popular for a variety of applications, including natural language processing, machine learning, and research. In particular, we will be discussing our recent experience using ChatGPT to study chaos theory and the many benefits that we have seen from using this tool. Our research highlights the potential of LLMs to speed up research efforts, improve accuracy, increase creativity and innovation, and support a wide range of applications in various domains. Whether you are a student, researcher, or educator, this blog will provide valuable insights into the use of LLMs in fostering education and research.
What are Large Language Models and How Do They Work?
Large language models are advanced artificial intelligence (AI) systems that are capable of processing and understanding human language. They are trained on massive amounts of text data and use this information to generate new text, answer questions, and perform a wide range of other natural language processing tasks.
LLMs are typically built using deep neural network architectures, which allow them to capture complex patterns and relationships in the text data that they are trained on. The training process for LLMs is computationally intensive and requires significant amounts of computational resources, such as powerful GPUs. During training, the model is exposed to large amounts of text data and is optimized to perform specific tasks, such as predicting the next word in a sentence or answering questions.
There are many different types of LLMs, each designed for a specific set of tasks and applications. For example, some LLMs are designed for language translation, while others are optimized for question-answering or sentiment analysis. LLMs have a wide range of applications, including natural language processing, machine learning, computer vision, and more. By leveraging the power of LLMs, researchers and developers can create advanced AI systems that can improve efficiency, accuracy, and creativity in a wide range of domains.
Benefits of Using Large Language Models in Research
A major benefit of using LLMs in research is improved accuracy. LLMs are designed to process and understand human language, which makes them ideal for tasks such as text generation, sentiment analysis, and question-answering. By using LLMs, researchers can obtain more accurate results compared to traditional methods, as LLMs are able to quickly and accurately process large amounts of text data. Additionally, LLMs can be fine-tuned for specific tasks and domains, which further increases their accuracy and effectiveness.
Also, the use of LLMs in research can also support increased creativity and innovation. By providing new and powerful tools for researchers to use, LLMs can support the development of new research ideas and approaches. Additionally, the vast amounts of data processed by LLMs can lead to new insights and breakthroughs in various domains, as LLMs can identify patterns and connections that might otherwise have gone unnoticed. Whether you are a student, researcher, or educator, the use of LLMs has the potential to greatly improve efficiency, accuracy, and creativity in research.
Concerns about Using Large Language Models in Education
One of the biggest concerns about using LLMs in schools is that students may become too reliant on them and may not develop their own critical thinking skills. LLMs are capable of providing instant answers to any question, but they do not encourage students to think critically about the information they are presented with. By relying on LLMs to provide answers, students may not see the value in putting in the effort to understand a subject in-depth or to form their own opinions. This could have a negative impact on their ability to analyze and evaluate information critically, which is a crucial skill for success in both academia and the workplace.
Another concern is that students may become less motivated to learn if they see LLMs as a quick and easy way to get answers. This could negatively impact their overall learning experience and their ability to retain information. Students may be less likely to engage with the material and may be more prone to forget what they have learned because they did not put in the effort to truly understand the material. This could result in lower test scores and poor academic performance.
Additionally, LLMs may not be as creative or original as text is written by a human. While they are capable of generating new text, they may not have the same level of creativity or originality as a human. This could lead to a decrease in creativity among students and could negatively impact their ability to express themselves in new and innovative ways. Students may be less likely to come up with new and original ideas because they have become too reliant on LLMs to generate ideas for them.
Potential ethical and privacy issues related to LLMs
One of the primary ethical concerns surrounding the use of LLMs in education is plagiarism. Students may use the model's output as their own work without proper attribution, which is considered academic dishonesty. This is because LLM-generated text can be so similar to existing text that it is difficult to distinguish between the two. For example, a student may use an LLM to write a paper on a given topic, and the output may be so similar to an existing paper that the student inadvertently copies portions of the original work without realizing it. In such cases, the use of LLMs raises ethical concerns about academic integrity.
Another important ethical concern related to the use of LLMs in education is privacy. LLMs require large amounts of data to be trained, and this data may include sensitive personal information. For example, a language model may be trained on text data that includes private messages, emails, or other sensitive information. There are concerns about how this data is collected, stored, and used, and how it may impact the privacy of individuals.
Research on the nonlinear system using LLMs
In the past, when I had to work on nonlinear circuits, writing the code for Lorentz attractor or Chua's circuit was a time-consuming task. I had to spend hours writing, compiling, and debugging code, which was a tedious and error-prone process. However, with the advent of large language models (LLMs), this has become an effortless task. The advantage of using LLMs in research is that they can be used as an extension of the search and writing process.
As an instance, here is the set of instructions, (also called a prompt) that I gave to the tool ChatGPT, available at https://chat.openai.com/chat while writing code for the nonlinear systems in python.


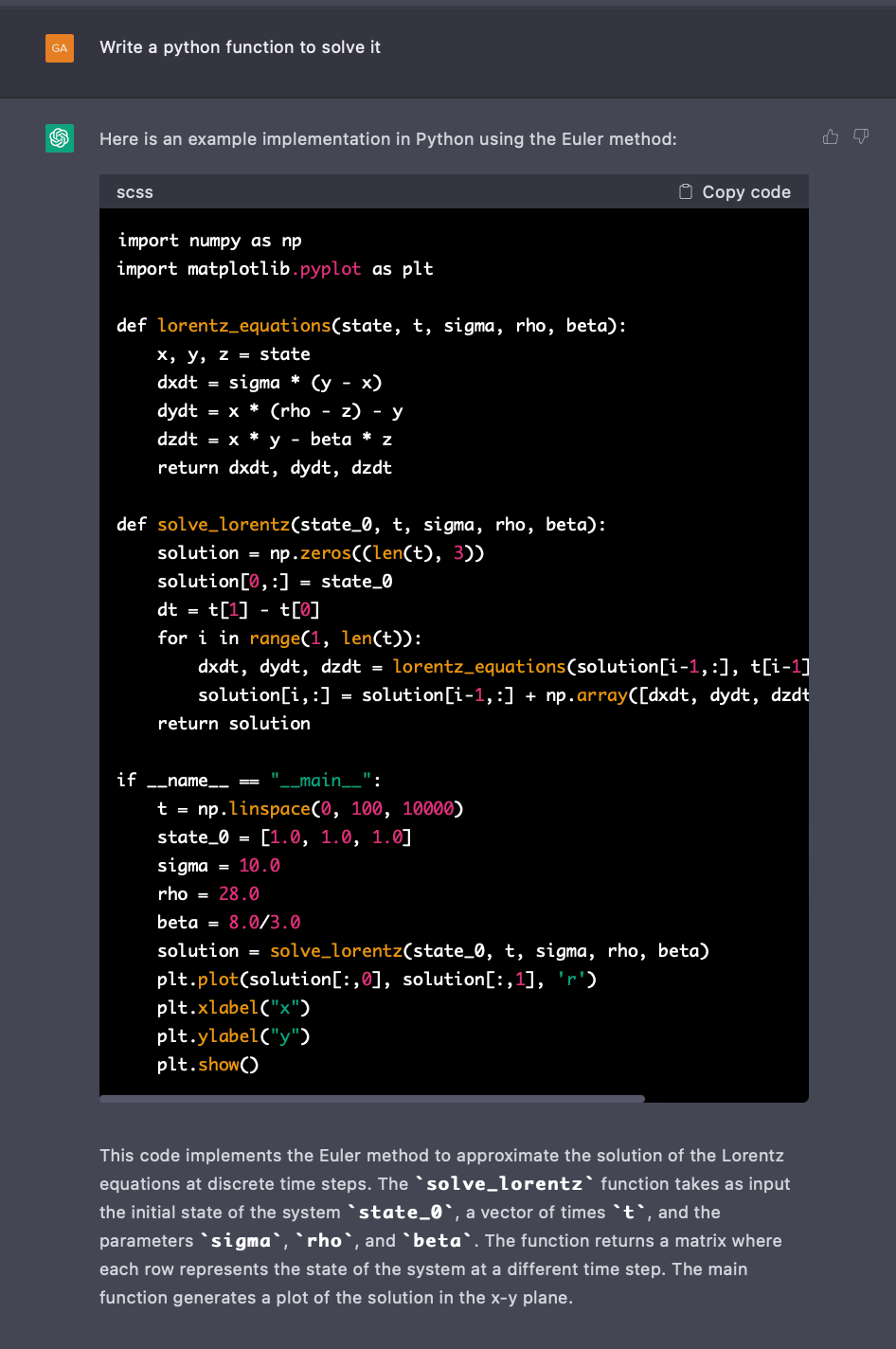
Upon realising that the code may be correct, I copied the code and tried to compile and run it on an online python interpreter. It is a tool provided by deepnote.com
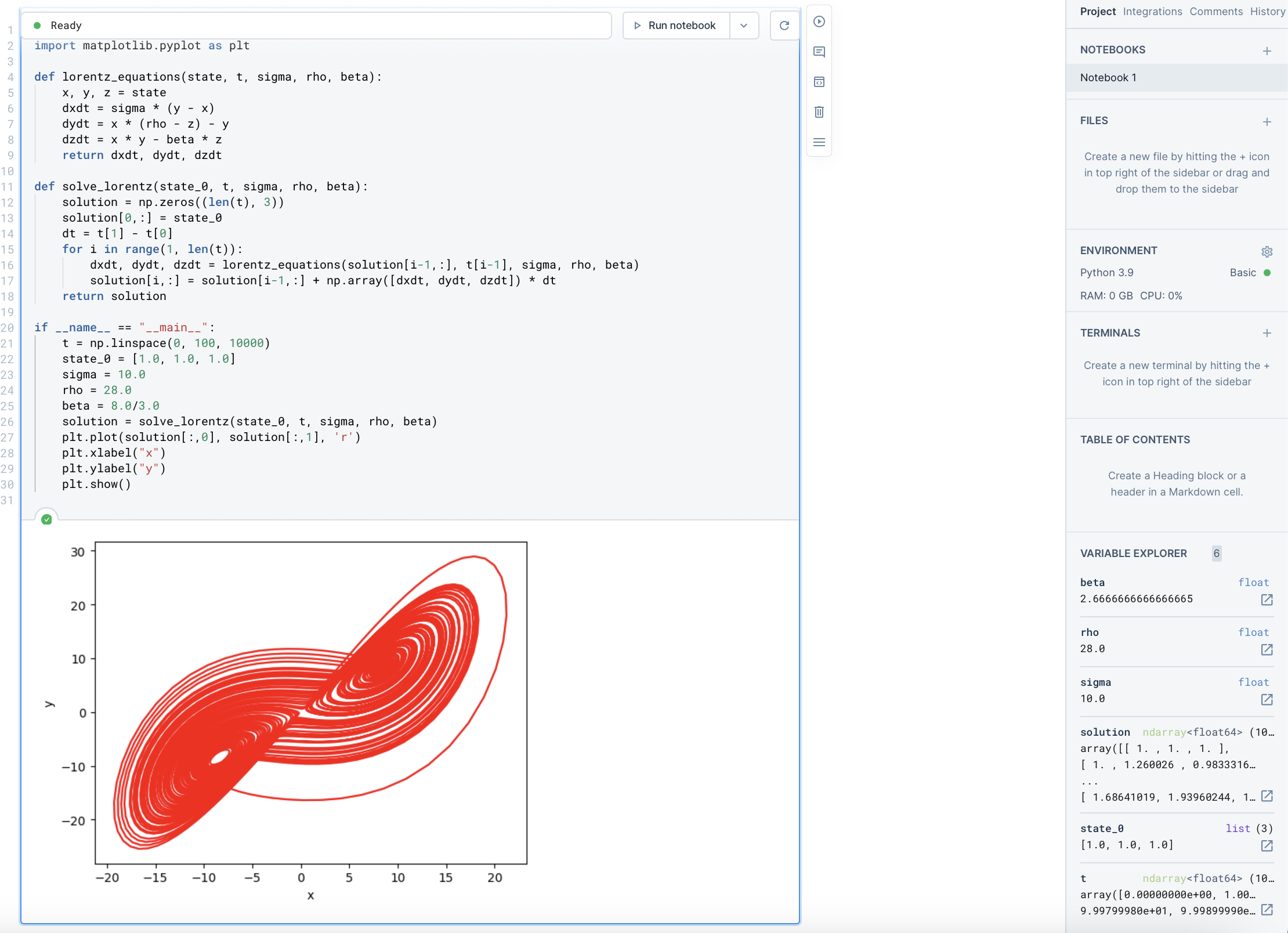
LLMs have not only boosted my productivity by reducing the time required from a couple of hours to 30-40 minute and minimizing the number of keystrokes needed, but they have also enabled me to focus on enhancing the task at hand instead of being bogged down by numerous software coding and compiling issues that tend to be cumbersome in research.
Studying the prior art
One of the biggest challenges in getting information from research papers is the volume of information that needs to be processed. Research papers can be quite lengthy, often running dozens or even hundreds of pages. To extract useful information from these papers, one must carefully read and analyze the text, identifying key concepts, results, and conclusions. This can be a time-consuming process, requiring significant effort and concentration.
Again in this case LLMs are coming to the rescue. https://elicit.org is a website which uses language models to help you automate research workflows, like parts of literature review. It helps find relevant papers without perfect keyword matches, summarize takeaways from the paper specific to your question, and extract key information from the papers. This helps find information way faster and makes it much more relevant.
It’s not all hunky-dori
Inspired by the above experiment, I tried to play with various other equations like duffing oscillator, simple sinusoidal oscillator, and Chua’s circuit among others. Not all cases were working out of the box. Some samples are as follows:

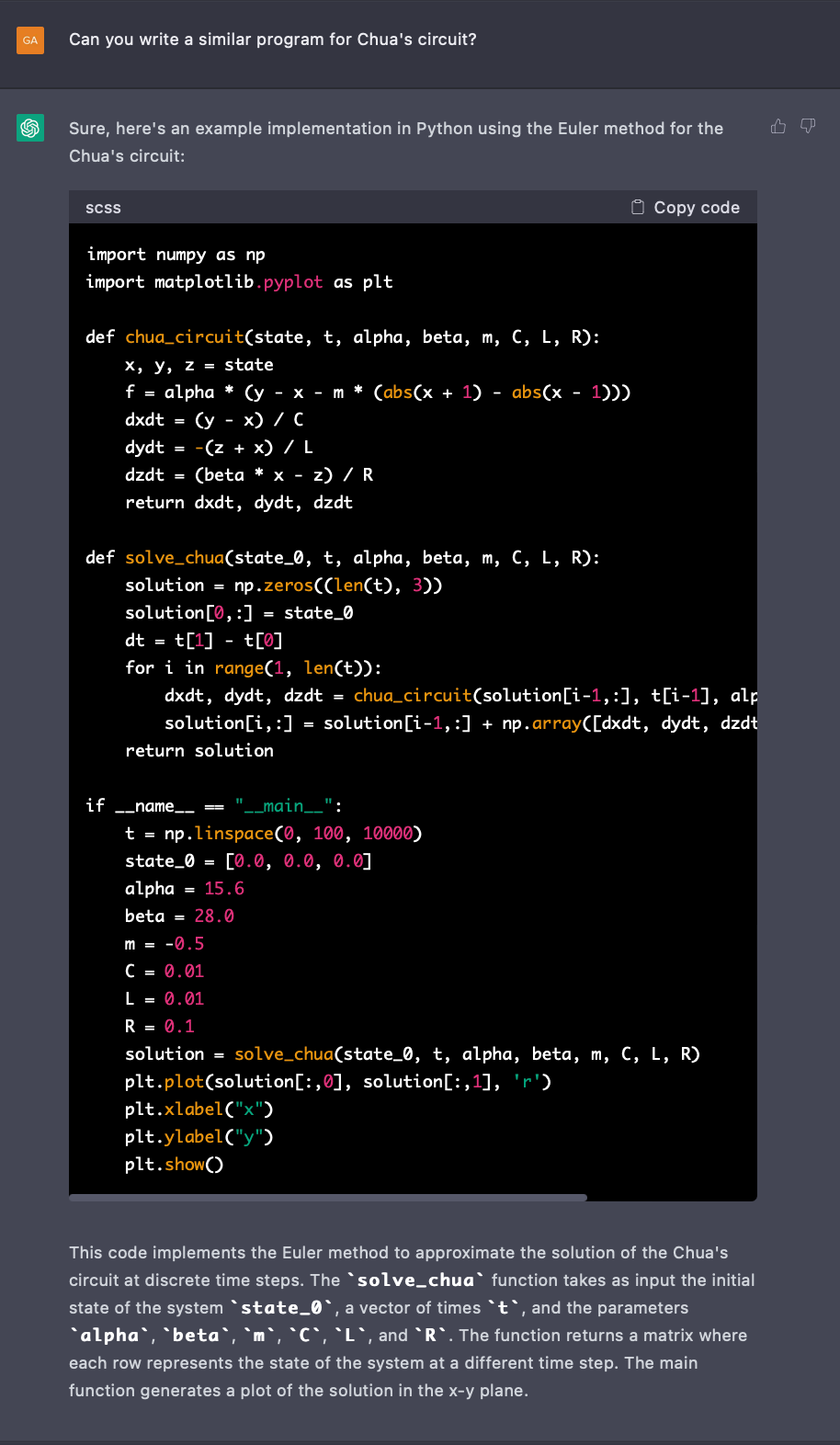
Now the above equation and solution, where it looks good are, however, erroneous. Rather than solving it myself, I tried to ask the system to do it for me. (One error spotted was though the generated code is written in python, the output suggests the code to be in a different language /format: java, scss etc)
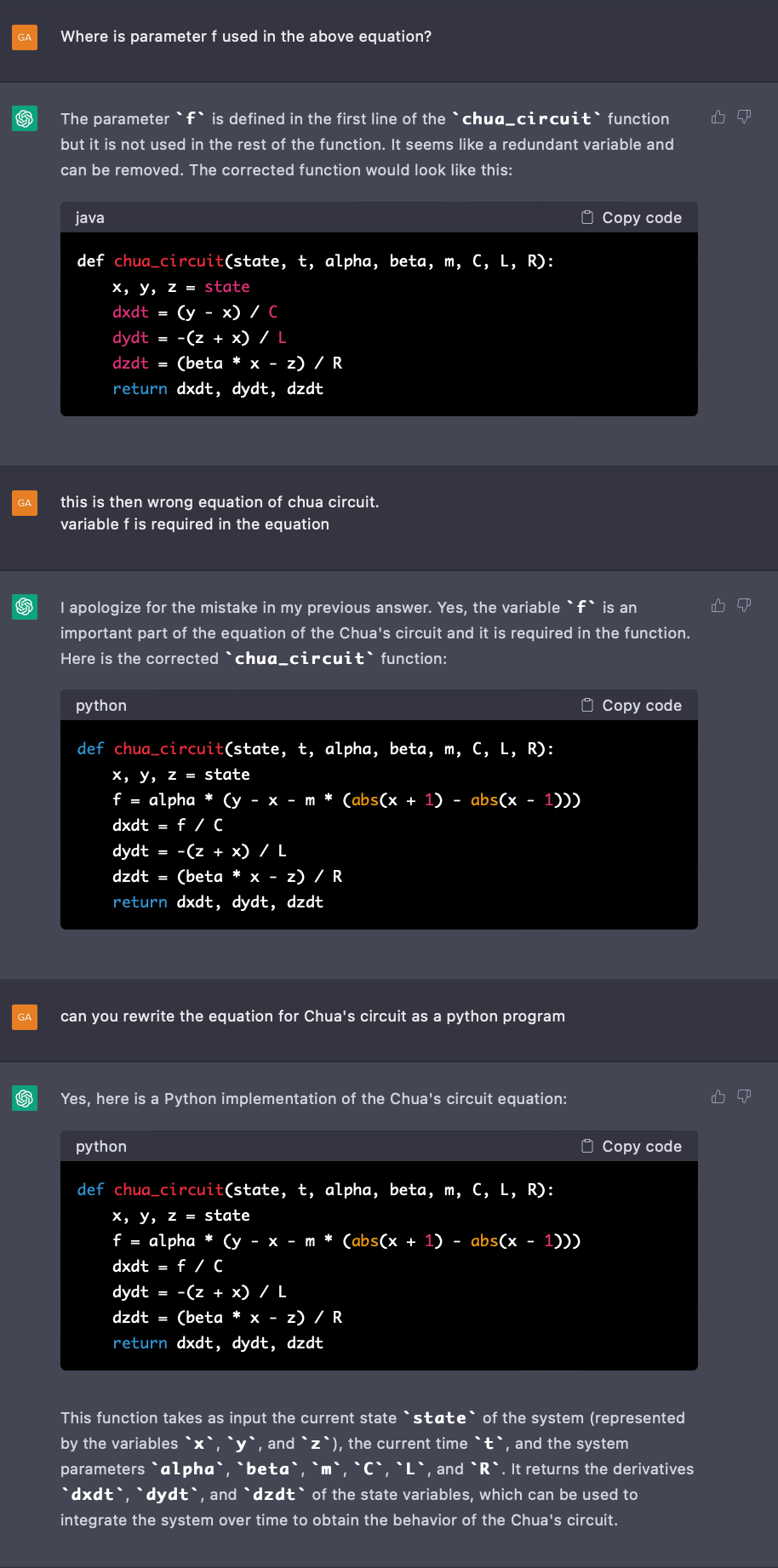
Whereas the tool is not able to provide a complete solution, it is nonetheless able to give a head start which can be quickly used to build the solution further.
Conclusion and discussion
This document discusses the use of large language models (LLMs) in education and research, including their benefits and concerns. The benefits of LLMs include speed and efficiency, improved accuracy, increased creativity and innovation, and applications in various domains. However, concerns include the lack of critical thinking, decreased motivation to learn, and decreased creativity among students. Additionally, there are potential ethical and privacy issues related to LLMs, such as plagiarism and privacy violations. The document also includes a case study of using LLMs to build Chua’s circuit and use it for further research and the benefits and limitations of this approach.
Curiosity and Learning
Large language models like ChatGPT are valuable resources that can inspire curiosity, promote learning, and provide quick and accurate information. By utilizing these models, people can broaden their knowledge and continue to expand their understanding of the world around them.
For instance, if I need to work on a new research project related to nonlinear circuits, I can use an LLM tool like ChatGPT to generate code for the Lorentz attractor or Chua's circuit. The LLM will present me with a solution, and I can edit anything that doesn't fit my research work. This not only saves me time but also reduces the chances of making mistakes, as the LLM has already done the hard work of generating the code.
The use of LLMs in research can be compared to spelling correction tools in the past. Just like spelling correction tools increase productivity by automatically correcting spelling mistakes, LLMs are helping to increase productivity in performing research by providing quick and accurate solutions to complex problems.
In this way, LLMs are helping researchers to focus on the creative and innovative aspects of their work, rather than spending time on repetitive and error-prone tasks. By freeing up time and reducing the chances of making mistakes, LLMs are helping to foster education and improve the overall quality of research.
High-level high-tech plagiarism
While large language models like ChatGPT can be very useful tools, there are some concerns about their potential impact on learning and creativity. For instance, Noam Chomsky finds the use of ChatGPT as “basically high-tech plagiarism” and “a way of avoiding learning.”
According to the quote:
For years there have been programs that have helped professors detect plagiarized essays,” Chomsky says. “Now it’s going to be more difficult because it’s easier to plagiarize. But that’s about the only contribution to education that I can think of.” He does admit that ChatGPT-style systems “may have some value for something,” but “it’s not obvious what.
Here are a few arguments that can be made against their use:
- Plagiarism: ChatGPT is trained on a vast amount of text data, and it can generate new text that is very similar to existing text. In some cases, people may use the model's output as their own work without proper attribution, which could be considered plagiarism. This can make it difficult for people to understand the importance of original thought and creativity.
- Lack of critical thinking: By relying too heavily on ChatGPT, people may not develop their own critical thinking skills. The model can provide quick and accurate answers, but it does not encourage people to think deeply about a subject, form their own opinions, or engage in creative problem-solving.
- Decreased motivation to learn: If people become too reliant on ChatGPT, they may become less motivated to learn on their own. They may see the model as a quick and easy way to get answers, and may not see the value in putting in the effort to learn a subject in-depth.
- Decreased creativity: ChatGPT can generate new text, but it may not be as creative or original as text written by a human. By relying too heavily on the model, people may not develop their own creativity or writing skills, which could negatively impact their ability to express themselves in new and innovative ways.
While large language models like ChatGPT can be useful tools for learning and information gathering, it is important to use them in moderation and to continue to develop critical thinking, creativity, and other essential skills. In fact, this post and subsequent posts used ChatGPT to put our thoughts, creativity and experiments out to a wider audience.
If you have read so far, don't miss the update on July 8, 2023
 Everyday Series
Everyday Series
References / Further reading
Here are some important papers on large language models:
- Attention Is All You Need by Vaswani et al. (2017) - This paper introduced the Transformer architecture, which has become a popular choice for large language models due to its ability to process input sequences in parallel.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Devlin et al. (2018) - This paper introduced BERT, a pre-trained language model that achieved state-of-the-art results on a wide range of natural language processing tasks.
- XLNet: Generalized Autoregressive Pretraining for Language Understanding by Yang et al. (2019) - This paper introduced XLNet, which improved upon the pre-training methods used in BERT by considering all possible permutations of the input sequence.
- GPT-2: Language Models are Unsupervised Multitask Learners by Radford et al. (2019) - This paper introduced GPT-2, a large-scale pre-trained language model that achieved impressive results on a wide range of language tasks.
- T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer by Raffel et al. (2019) - This paper introduced T5, a unified text-to-text transformer that can be fine-tuned on a wide range of natural language processing tasks.
These papers have been instrumental in advancing the field of natural language processing and are highly recommended for anyone interested in large language models.
Here are some important papers on Chua's circuit:
- Chua, L. O. (1986). The genesis of Chua's circuit. Archiv für Elektronik und Übertragungstechnik (AEÜ), 40(6), 382-384.
- Gaurav Gandhi, Gyorgy Cserey, John Zbrozek, and Tamas Roska, Anyone Can Build Chua's Circuit: Hands-on-Experience with Chaos Theory for High School Students. International Journal of Bifurcation and Chaos, Vol. 19, No. 04, pp. 1113-1125 (2009)
- Kennedy, M. P., & Chua, L. O. (1990). The origins of Chua's circuit equations. IEEE Transactions on Circuits and Systems, 37(4), 436-447.
- Matsumoto, T., & Chua, L. O. (1987). Chua's circuit—A paradigm for chaos. IEEE Transactions on Circuits and Systems, 34(10), 1203-1220.
- Lorenz, E. N. (1976). The Lorenz equations: a nonlinear deterministic system. The Mathematical Scientist, 1(1), 1-23.
Noam Chomsky’s views: Noam Chomsky: The False Promise of ChatGPT, New York Times, Mar 8, 2023
https://www.nytimes.com/2023/03/08/opinion/noam-chomsky-chatgpt-ai.html
Acknowledgement
I would like to thank Gaurav Sood, one of our readers, a well-wisher and a good friend for his review of these notes.
Note
The original article was published on Notion and was constantly updated.

Want more insights and information on AI or want to get involved?
- Reply back, email, ask questions and share feedback. I answer every message and email.
- We have a vibrant WhatsApp group. If you want to join that, please reach out to me.
- Check-out previous posts here and research papers summaries here.
- Do follow us on our social media where we post micro-byte information daily.
YouTube: http://youtube.com/@everydayseries
TikTok: https://www.tiktok.com/@everydayseries
Instagram: http://instagram.com/everydayseries_
Twitter: http://twitter.com/everydaseries_



