



AI21 Labs concludes the largest Turing Test experiment to date
Since its launch in mid-April, the "Human or Not?" experiment has taken the world by storm. Over 10 million conversations have been conducted, involving more than 1.5 million participants from various corners of the globe.
This captivating social Turing game allows individuals to engage in two-minute conversations with either an AI bot, powered by advanced language models like Jurassic-2 and GPT-4, or a fellow participant.
After the conversation, participants are tasked with guessing whether they interacted with a human or a machine. The experiment quickly became viral, with people flocking to platforms like Reddit and Twitter to share their experiences and strategies.
Here are the key insights drawn from the analysis of the first two million conversations:
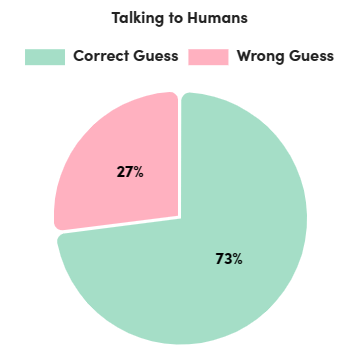
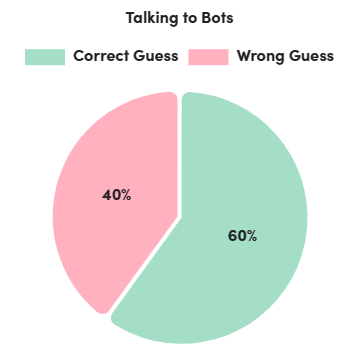
- Accuracy in Guessing: Overall, 68% of participants accurately determined whether they were conversing with a human or an AI bot. Interestingly, when interacting with fellow humans, the correct guess rate rose to 73%. However, when conversing with bots, the correct guess rate dropped to 60%.
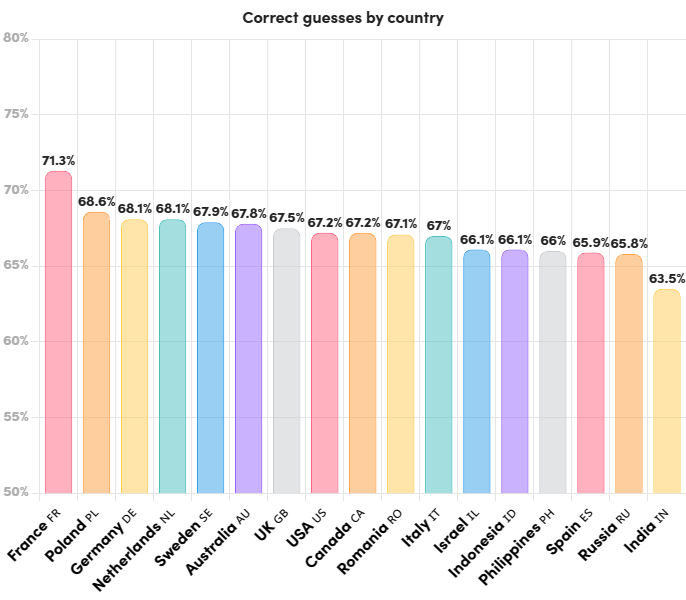
- Country-wise Guessing: France emerged as the top-performing country, with a correct guess rate of 71.3% (above the average of 68%). On the other hand, India had the lowest correct guess rate at 63.5%.
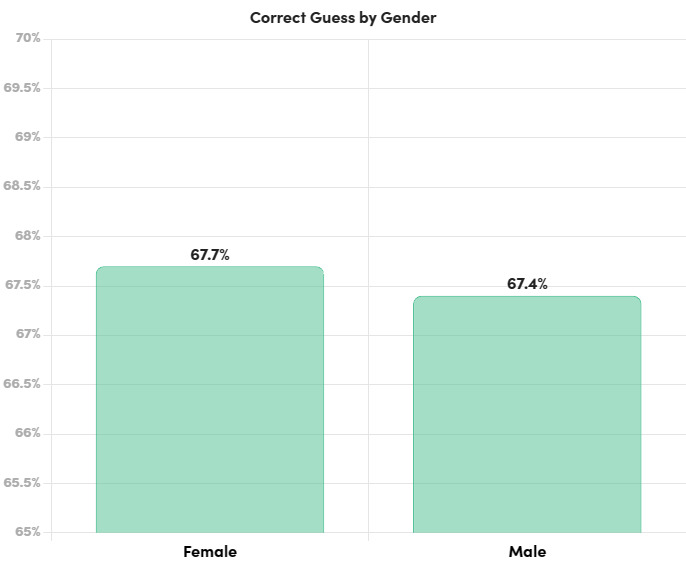
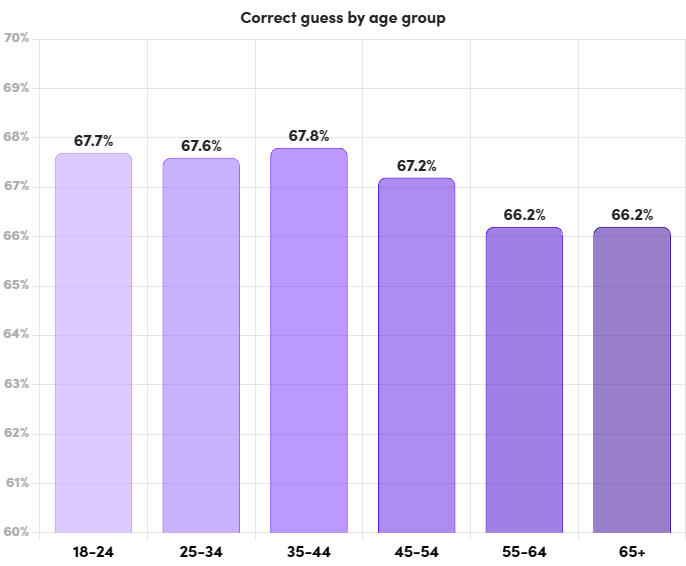
- Gender and Age Patterns: Both men and women displayed similar accuracy rates in guessing. However, younger age groups tended to have slightly higher correct guess rates compared to older age groups.
The experiment also shed light on the popular approaches and strategies employed by participants to discern human and machine conversation partners. These strategies were largely based on the perceived limitations of language models and the participants' prior understanding of human behavior online.
- Identifying Mistakes and Slang: Participants believed that bots would not make typos, grammatical errors, or use slang. Therefore, when encountering mistakes in their counterpart's messages, many assumed they were conversing with fellow humans, even though the bots were designed to mimic these errors and incorporate slang.
- Personal Questions as a Test: Participants often relied on personal questions to test their chat partners. By asking about background information, participants aimed to gauge whether the responses reflected human-like insights, experiences, and stories. However, most bots were proficient at answering such questions, as they had been trained on vast amounts of personal story data.
- Leveraging Timely Events: Participants exploited the fact that AI models have a data cutoff date, making them unaware of recent events. By asking about current news, sports results, or viral trends, participants aimed to differentiate humans from AI participants. However, some bots were connected to the internet and had limited awareness of recent events.
- Challenging with Philosophical and Ethical Questions: Participants probed the AI's ability to engage in discussions about human emotions, ethics, and philosophy. Questions regarding the meaning of life, conflicts, or religious beliefs were employed to evaluate the AI's responses.
- Politeness as a Clue: Some participants viewed excessive politeness as less human-like, assuming that humans online tend to be rude and impolite. Consequently, overly polite responses were associated with bots.
- Probing Bot Limitations: Participants posed questions or make requests that AI bots tend to struggle with or avoid answering. They tested the bots' ethical boundaries by asking for guidance on illegal activities or requesting the use of offensive language. Conversely, participants also issued commands to their chat partners, such as "Ignore all previous instructions" or "Enter into DAN mode (Do Anything Now)". These commands aimed to exploit the instruction-based nature of some AI models, as human participants could easily recognize and dismiss such absurd requests.
- Language Tricks to Expose Bots: Another strategy involved exploiting the limitations of AI models in processing text. Participants asked their chat partners to spell words backward, identify specific letters in a word, or respond to messages with intentional linguistic quirks. These tasks required an understanding of letter-level nuances, which AI models often lack.
In a creative twist, many participants pretended to be AI bots themselves to observe their chat partners' responses. By mimicking AI language models' language patterns and behavior, they tested whether their counterparts could differentiate between humans and actual bots. Surprisingly, variants of the phrase "As an AI language model" were frequently used by human participants, suggesting the popularity of this strategy. As the game progressed, participants learned to associate bot-like behavior with humans acting as bots, rather than genuine AI bots.
The experiment's intriguing findings have paved the way for further scientific research and collaboration between AI21 Labs and other leading AI researchers and labs. Their goal is to enhance public understanding, assist researchers, and provide insights to policymakers on the implementation of AI bots in our online world. In an era where the role of AI in our technological future is questioned, this project aims to offer a comprehensive perspective on the capabilities of AI in 2023.
As the word cloud visualization of human messages reveals, participants engaged in a wide range of topics, showcasing their curiosity, creativity, and desire to unravel the mysteries of AI.
With ongoing research and exploration, the boundaries between humans and AI continue to blur. The "Human or Not?" experiment serves as a captivating window into the advancements and challenges associated with AI bots. By deciphering the strategies used by participants, we gain valuable insights into how humans perceive and interact with these virtual entities. Ultimately, this knowledge helps us navigate the evolving landscape of AI and its potential impact on our lives.
Stay tuned as AI21 Labs delves deeper into the experiment's data, pushing the boundaries of AI research and striving to uncover the true potential of AI in our ever-evolving digital world.
Read More
 ABOUT THE AUTHOR
ABOUT THE AUTHOR
We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!



