



Imagine a world where musicians compose symphonies without playing a single note, indie game developers infuse virtual realms with lifelike sounds on a shoestring budget, and small business owners effortlessly add captivating soundtracks to their social media posts. This is the enchanting realm that AudioCraft, a framework for generative AI in audio, ushers in. The journey to open-sourcing this innovation is set to revolutionize the way we interact with sound, enabling accessibility and creativity for all.
The AudioCraft Revolution
At the heart of the AudioCraft revolution are three ingenious models: MusicGen, AudioGen, and EnCodec. These models herald a new era by generating authentic audio and music from simple text-based inputs. What sets AudioCraft apart is its training approach—it hones its skills on raw audio signals, not confined by the limitations of MIDI or piano rolls.
In the present day, a closer examination is directed towards the revelation of an upgraded rendition of the EnCodec decoder. This evolutionary step holds the pledge of elevating the quality of music generation, while concurrently minimizing the presence of artifacts. Moreover, the introduction of the pre-trained AudioGen model is presented, conferring upon users the ability to conjure an assortment of sounds, spanning from the barks of canines to the blaring horns of cars, all through the medium of textual inputs.
However, this disclosure encompasses more than just these advancements; the comprehensive ensemble of AudioCraft's model weights and code has been made available, marking a daring initiative aimed at expediting the advancement of AI in the realm of audio.
Translating Text into Harmonies
In a digital age where generative AI models have transformed images, videos, and text, the realm of audio innovation appeared to lag. However, AudioCraft emerges as the beacon of change, bridging this gap. Complexities arise when generating music—a dance of local and global patterns, intricate notes, and harmonious structures. Prior attempts leaned on symbolic representations like MIDI, but these fell short in capturing the essence of music. Recent strides leverage self-supervised audio representation learning, but the potential for advancement remained untapped.
The AudioCraft family of models sweeps in, delivering high-quality, consistent audio through a natural interface. By simplifying generative models' design, AudioCraft empowers users to harness Meta's years of pioneering work. Beyond this, it sparks innovation by allowing users to push boundaries and develop their custom models.
A Symphony of Techniques
Creating lifelike audio from raw signals is akin to molding intricate sculptures from vast blocks of marble. AudioCraft conquers this challenge by transforming raw signals into discrete audio tokens using the EnCodec neural audio codec. This novel vocabulary serves as the building blocks for autoregressive language models, orchestrating the generation of new sounds and music.
The EnCodec neural codec stands as the cornerstone, training to compress and reconstruct audio with remarkable fidelity. It engineers streams of audio tokens, each capturing a layer of information from the audio waveform. This multidimensional approach ensures accurate reconstruction and fidelity of the generated audio.
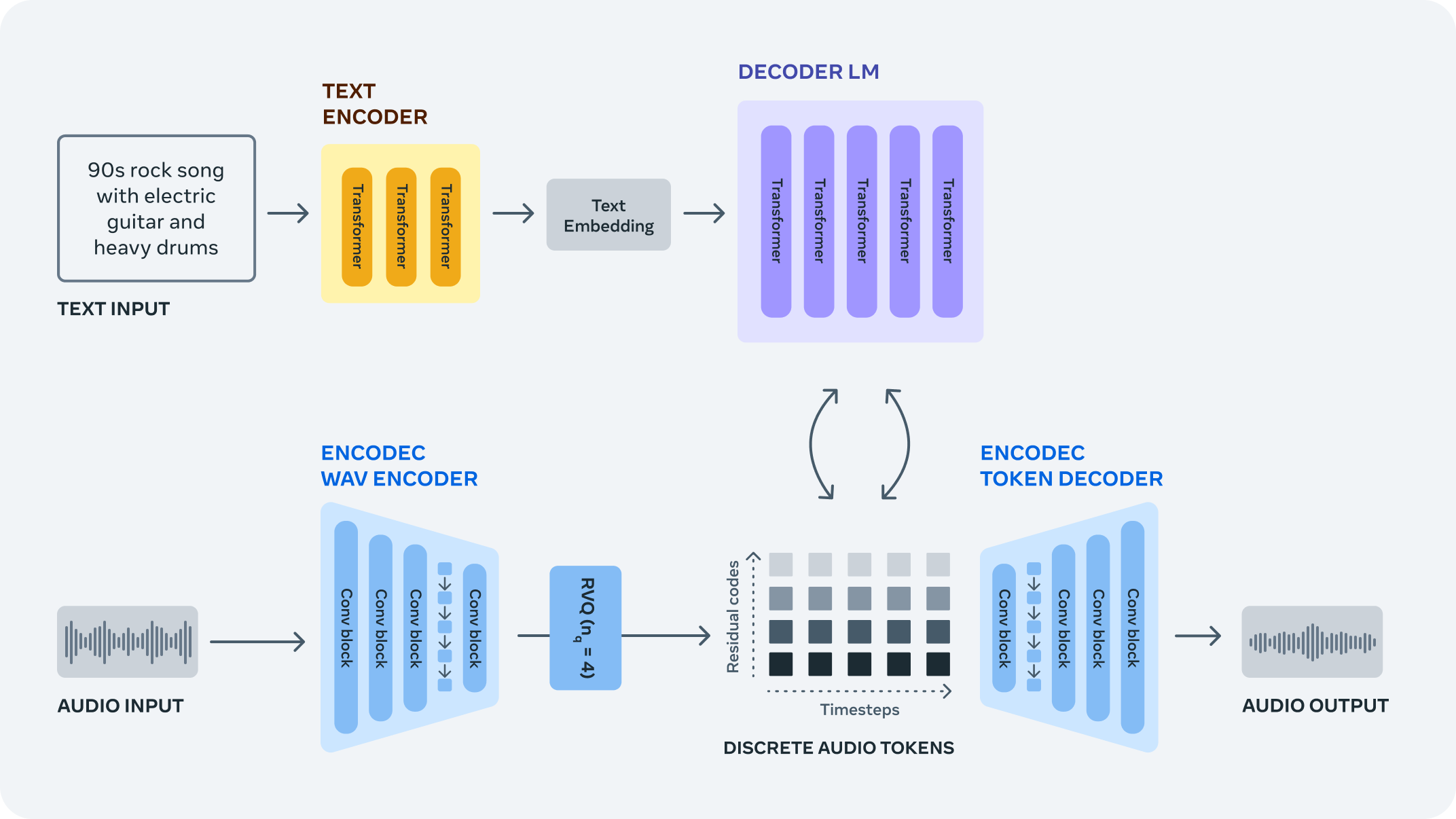
Elevating Artistry through Open Source
AudioCraft isn't just about innovation; it's about empowerment. It facilitates the creation of sound generators, compression algorithms, and music generators, all within the same dynamic codebase. The models' accessibility invites researchers and practitioners to refine, reimagine, and reshape the future of audio.
Responsibility and transparency form the bedrock of this journey. Recognizing the limitations in training datasets, the creators of AudioCraft open the door for collaboration. By releasing the code, they encourage others to address potential biases and enhance the models' potential.
A Symphony of Possibilities
As the AudioCraft family of models takes its first steps, its potential becomes evident. The horizon holds the promise of faster prototyping, enhanced iteration, and enriched human-computer interaction through generative AI. Whether you're crafting a grand symphony or perfecting the ambiance of a virtual world, AudioCraft propels the realm of sound into uncharted territory.
In the symphony of innovation, AudioCraft's melody is harmonizes accessibility, creativity, and technological advancement. The era of generative AI in audio has dawned, promising a future where everyone, from musicians to entrepreneurs, can shape soundscapes in ways never before imagined. The stage is set, the code is open, and the music of the future is calling.
Read More:


We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!



