QLoRA

The landscape of AI fine-tuning is about to undergo a transformative shift with the introduction of QLoRA, a groundbreaking 4-bit method that enables efficient model refinement on single professional and consumer GPUs. This cutting-edge approach not only rivals the performance of expensive 16-bit techniques but also significantly reduces costs, making AI development more accessible than ever before.
Traditionally, fine-tuning AI models required substantial resources and specialized hardware. However, QLoRA is set to change the game by democratizing the process and fostering open-source advancements. With this breakthrough, personalized AI models could soon be within reach, even on mobile phones.
QLoRA's Impact on AI Fine-Tuning
The release of QLoRA marks a major milestone in the field of AI fine-tuning. Researchers have developed a method that achieves performance comparable to existing techniques at a fraction of the cost. This advancement holds tremendous potential for a wide range of applications, including personalized chatbots and open-source language models.
Understanding the Methodology
QLoRA builds upon the success of the LoRA approach, a popular and cost-effective method for enhancing AI models. Rather than retraining models from scratch, LoRA allows researchers to refine existing pretrained models, improving their performance and adaptability. This method has already contributed to the development of advanced language models like Vicuna and Alpaca, which have demonstrated the capabilities of open-source models.
QLoRA goes a step further in terms of efficiency by introducing several key innovations:
- 4-bit NormalFloat Data Type: QLoRA employs a 4-bit NormalFloat data type, which not only reduces memory usage but also maintains better precision compared to traditional 4-bit data types like integers and floats.
- Double Quantization Method: By quantizing the quantization constants themselves, QLoRA optimizes memory usage even further, enhancing efficiency during the fine-tuning process.
- Paged Optimizers: QLoRA incorporates Paged Optimizers, a memory management technique that effectively handles spikes associated with processing longer data sequences. This innovation contributes to smoother and more efficient fine-tuning.
Achieving Vast Efficiency Gains
The most impressive aspect of QLoRA is its ability to significantly reduce the memory footprint during model fine-tuning. For instance, a 65-billion parameter chatbot fine-tuned with QLoRA exhibited performance on par with a 16-bit fine-tuned counterpart but required only 48GB of GPU memory, compared to a massive 780GB for the latter. This breakthrough makes it possible to fine-tune even the largest public models on single professional GPUs like Nvidia's A100.
Moreover, QLoRA has proven its efficiency on consumer GPUs as well. The researchers successfully trained a 33-billion parameter model on a 24GB consumer GPU in less than 12 hours, achieving the same performance as the 16-bit baseline. These results demonstrate the remarkable capabilities of QLoRA even on hardware that is more readily available to the average user.
Benchmarking and Evaluating Performance
To assess the performance of various AI models, the researchers conducted a tournament-style benchmarking approach, involving both GPT-4 and human annotators.
Despite the limitations of the Vicuna benchmark, it still provides valuable insights into the performance of AI models. In the case of QLoRA, the fine-tuned Guanaco models, with parameters ranging from 33 billion to 65 billion, achieved impressive results. When compared to ChatGPT-3.5 Turbo, the Guanaco 65B model attained 99.8% of its performance on the Vicuna benchmark, while the Guanaco 33B model, trained on a 24GB consumer GPU, reached 97.8%.
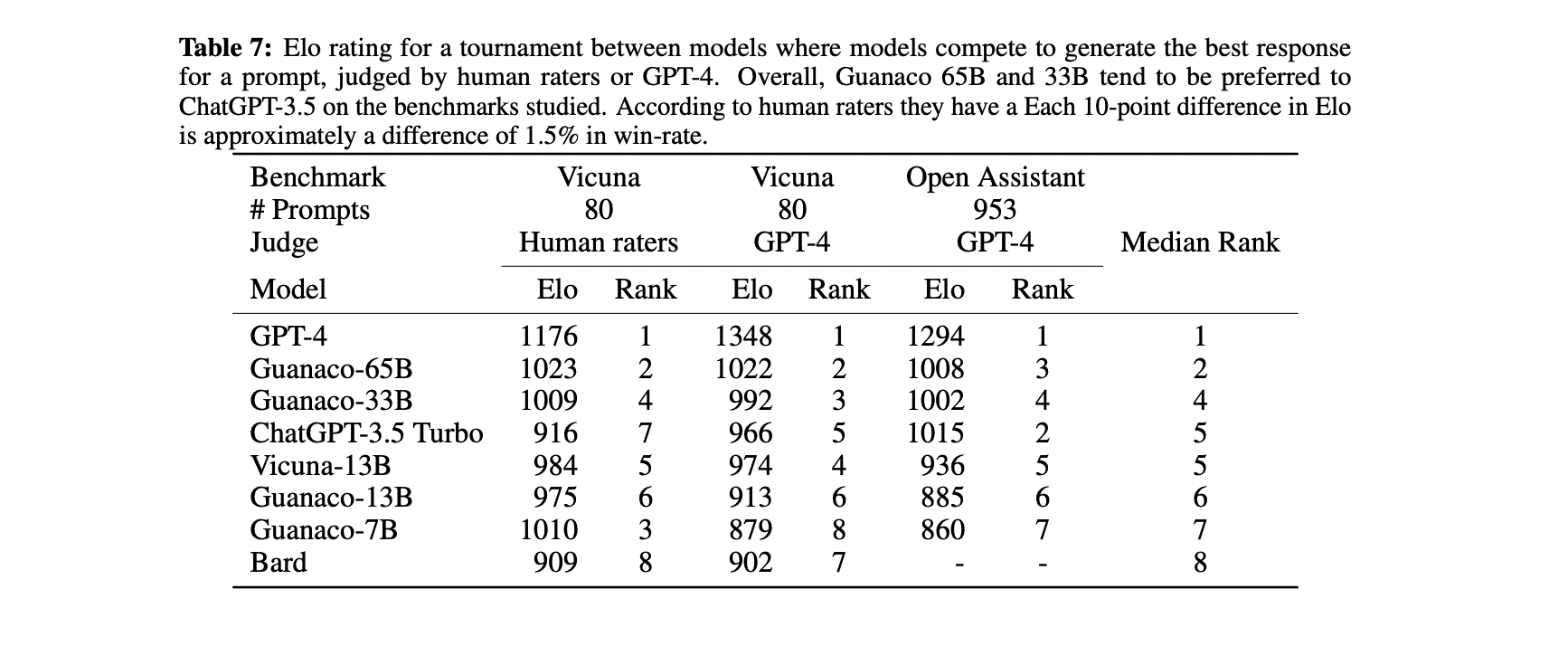
QLoRA's performance across the human and GPT-4 evaluation in various benchmarks, was conducted in a tournament-style contest. Photo credit: arXiV
It's worth noting that agreement between systems varied, and human annotators themselves had differing preferences for responses. Nonetheless, the performance of the Guanaco models stood out in terms of their appeal to both GPT-4 and human evaluators across the 80 prompts in the Vicuna benchmark.
Enabling User Interaction and Future Implications
To enable readers to experience and assess the quality of responses generated by Guanaco models, the researchers have provided an interactive app for testing. This opportunity for user interaction not only showcases the capabilities of the fine-tuned models but also highlights the potential for personalized AI on a broader scale.
The implications of QLoRA are significant, both in terms of advancing AI development and democratizing access to cutting-edge language models. With QLoRA's efficient memory requirements, the development of new models no longer necessitates expensive computing resources. Moreover, QLoRA's potential to fine-tune models on mobile devices could unlock personalized AI experiences with enhanced performance while maintaining data privacy.
The open-source community stands to benefit greatly from QLoRA's availability. The 4-bit quantization feature is now integrated into Hugging Face transformers, making it easier for researchers and developers to adopt and leverage this innovative approach.
The arrival of QLoRA heralds an exciting new era for AI fine-tuning. As Andrej Karpathy, OpenAI lead researcher, aptly summed it up, "Wow, very nice 'full-stack' release." With QLoRA's capabilities, AI enthusiasts can look forward to pushing the boundaries of AI development, unlocking novel applications, and embracing the possibilities of personalized language models.
Reference Links
[2305.14314] QLoRA: Efficient Finetuning of Quantized LLMs (arxiv.org)

We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!
No spam, no sharing to third party. Only you and me.